My daughter won first prize in a poster session at UW Madison, presenting her work on “Evaluating Retrieval-Augmented Generation vs. Long-Context Input for Antibiotic Timeline Extraction from EHRs”. I struggled to follow it, but got the gist of it — they’re working on methods to more efficiently extract information from patients’ medical records using LLMs. She sent us the poster image, maybe you can extract more details from it.
Near as I can tell, it’s perfect, and her peers also thought so. The only suggestion I could possibly make is to maybe add a few spider photos…or a picture of my granddaughter? I don’t know that my suggestions would necessarily help.
It’s nice to have a vague idea of what she’s been up to!

LLMs, eh?
I know you yourself are not that keen on them.
Also, I can’t deny your pride in Skatje and her accomplishment and her career trajectory is very well founded. Next-gen!
(A rather empirical take; more like ‘applied’ than ‘theoretical’ best as I can tell)
From the title it sounds like the comparison is between RAGs and long contexts, but in the results it just uses “recent notes” and a rules -based method as the baseline. It would have been good to see long context results for comparison, though, since it represents the high-cost high-quality option.
RAGs are good if there is a lot of information and only small portions of it will be relevant. They’ve become less popular recently because advances in context reuse and caching made them less necessary.
While not ground-breaking it’s a useful result. I’d be interested in seeing how multimodal data from EHRs could be integrated as well, but I guess that’s a bit too close to state-of-the-art…
This is exactly the implementation of LLMs where I’ve seen them provide real value. Tightly controlled training data sets, integrating and collating information to suggest possibilities to the operator which they may not consider. Nothing that a human being couldn’t do given time, but a physician would only be able to mange a single patient if they were also required to collate and integrate all the data available.
The risk of hallucinations is lower, and hopefully the person getting the results has enough experience and common sense to evaluate them. An expert should be able to know if it passes the smell test.
This is a far cry from an LLM which has been trained on everything, accurate or not, on the internet.
Can’t understand the title! I am getting so old…
@ ^ nomdeplume : Its above my head and well outside my jurisdiction too. Soo i don’t know enough but lloks and seems prety impressive to me.
Congratulations to PZ’s daughter from me.
I concur with StevoR. Over my head, but cool stuff. Congrats.
I have a MSEE, read vociferously, and have what I believe is an extensive vocabulary. I studied that title for several minutes. I understand the meanings of every word (save the EHR acronym) but, for the life of me, I haven’t the foggiest notion of what it means. I suspect it wasn’t formulated with me in mind.
Not that complicated, conceptually.
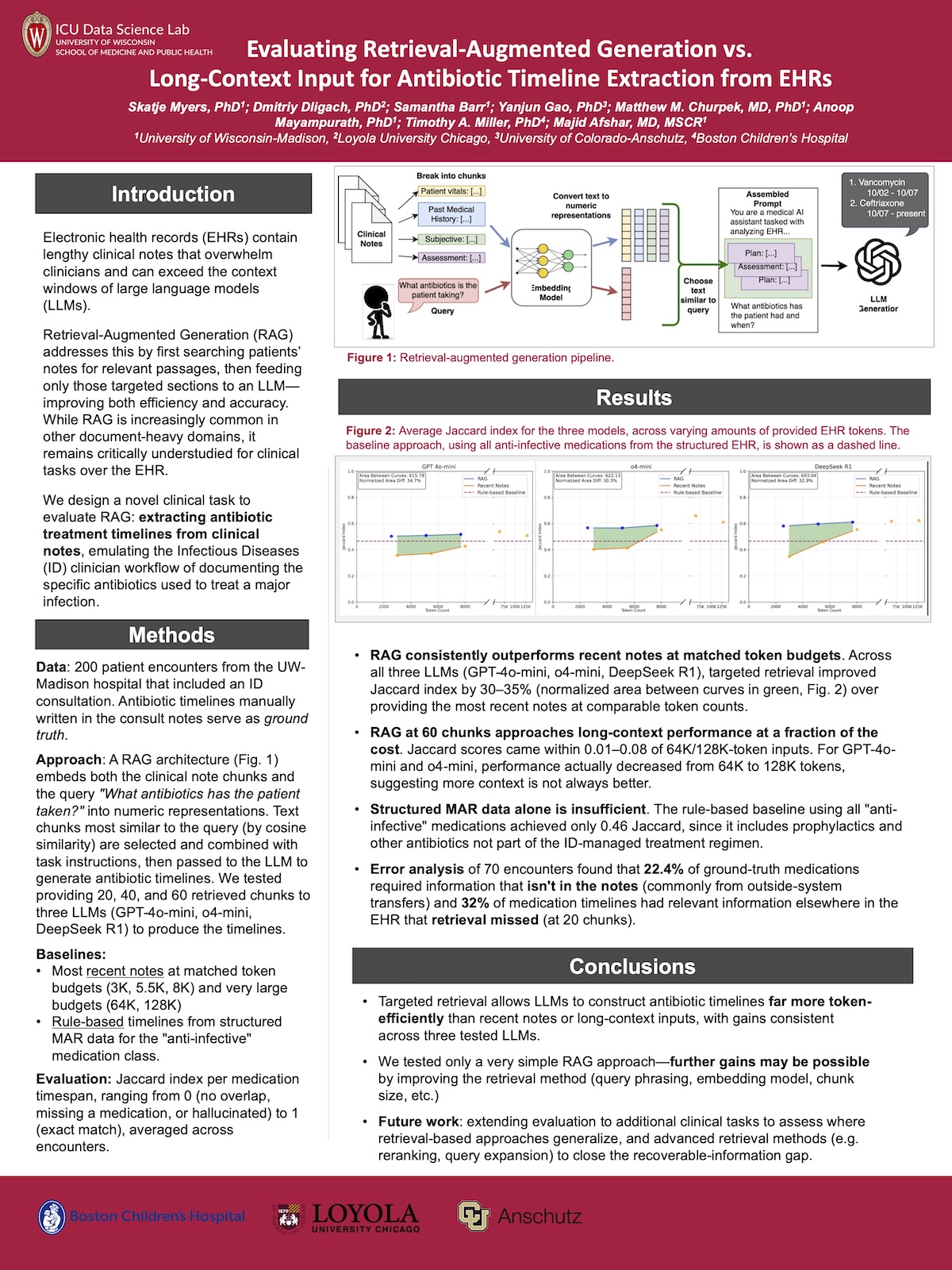
The title (misleadingly IMO) says it’s comparing two AI methods for mapping patient antibiotic histories from digital medical charts (EHRs): retrieving specific information via RAG versus processing the entire, long-context document.
The conclusions show 3 methods were actually assessed:
1. Targeted Text Retrieval (RAG): Extracting task-relevant passages from the patient’s entire record;
2. Most Recent Clinical Notes (Truncation Baseline): Providing only the latest chronological notes to simulate standard strict token limits;
and
3. Full Context Window (Long-Context): Utilizing the model’s entire expanded context window (up to 128K tokens) to ingest the full hospital stay.
—
It’s surely a nod to the limitations of current LLMs that the full context yields lesser results than RAG.
(Also, 128 tokens are the equivalent of 1960s memory modules. Very very small)
@2 The long-context inputs are the 64K and 128K versions of “recent notes”. “Recent notes” just describes how we filled the window when not using RAG (chronologically vs. retrieval-selected), so we’re comparing them at matched token budgets and then showing performance of the “recent notes” all the way out to very long contexts (there’s no point in doing RAG when most or all of the encounter notes are within the token budget, hence the RAG result line doesn’t extend further right).
Caching helps with cost when re-using context repeatedly, but doesn’t fix lost-in-the-middle or noise from irrelevant context. The use of data stores and RAG have continued to be popular in many applications when drawing on large data sources.
—
Pre-print here, though this is out-of-date — the latest version actually uses three newer models as well as an additional embedding model, and the same trends and conclusions hold. I’m just still fighting with arXiv’s latex compiler to get it updated on the site.
Also, for context, this was an internal award at a research day in our division, where I won at the postdoc/fellow trainee level. Lots of other really amazing research going on at UW!
Apologies for my typos in #5. I was rushing and, as usual, saw what I thought I’d typed rather than what I actually had and didn’t realise until after I’d clicked submit.
I did notice that in the featured image, the featured models are at least a year old.
PZ, congratulations to Skatje for her work and to you for your fatherly help and encouragement.
The measurements (Jaccard indices) are all relative, comparing the different methods to each other. However if I am reading correctly, there is an absolute comparison (to ground truth, i.e. human analysis of the physician notes) implicit in: “0 (no overlap, missing a medication, or hallucinated) to 1 (exact match)” — and the best graphed values are about 0.62.
Based on that — which to a naive passer-by sounds pretty darn feeble — would the investigator recommend using an LLM to analyze real patient records?