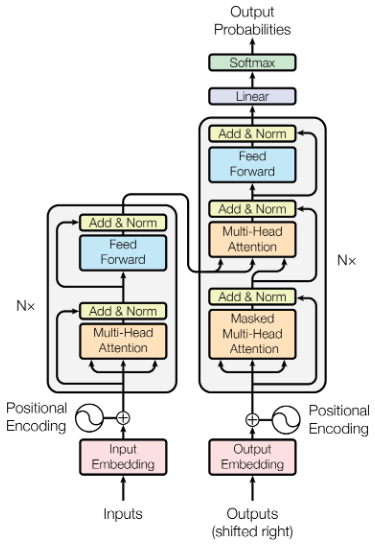
This is the final part of my series reading “Attention is all you need”, the foundational paper that invented the Transformer model, used in large language models (LLMs). In the first part, we covered some background, and in the second part we reviewed the architecture of the Transformer model. In this part, we’ll discuss the authors’ arguments in favor of Transformer models.
Why Transformer models?
The authors argue in favor of Transformers in section 4 by comparing them to previously extant options, namely recurrent neural networks (RNNs) and convolutional neural networks (CNNs).