But it’s not, I swear! As far as I recall, the number of products or services that I have actually gotten excited about is, maybe, a dozen. I suppose that’s a side-effect of living in the past, where if someone comes up and wants to show me a new Tactical(r) self-defense cane, I’m going to be comparing it to long-established products like the Henschel VK4501 (aka “King Tiger”) which is almost certainly superior unless you are going on a plane.
This is more about AI. Remember back in 2017 when the state of the art in AI image manipulation was this:
-

- Adding AI extension textures to a plain image like this gives you…
-

- … ball bearings on mushrooms
That was before a whole layer of new process was added, to map words to concepts, to use oppositional mapping to decay the likelihood of getting things we won’t like, etc., etc. Once the software got to the point where it could be hosted in the cloud, or run on a desktop, the stuff really took off. When Dall-E first came out (remember!?) part of what made it so important was that you didn’t have to do anything to run it – just go to a URL, enter some text at a prompt, and click go – it was easy enough for even today’s technology journalists to figure out. [In a sense, if you’re running it on a desktop, the checkpoint/knowledge-base construction with billions of inputs is still being done in the cloud) anyhow, I pretty quickly decided that Dall-E could decorate my blog postings with a bit of extra absurdity, but frankly it wasn’t very good. Then, I heard about Midjourney and mentioned that a fair bit here. I was unhappy with Midjourney, as I tend to be with all of the AI generator sites that exclude erotica but provide endless violence. I’m a bit on the fence about the question of AI-generated erotica, since it raises some deep questions about “what is the overall point of this, anyway?” and that’s without getting into the issues about sin, victimless crime, or thought-crime. Those are complex issues and I don’t think that requiring your AI to make pleasant images is the way to do it.
In a related but unrelated issue, a current fad is to create things “in the style of studio Ghibli” knowing that it takes minutes off of Hayao Miyazaki’s life every time he sees data-driven copies of his life’s work. It has gotten so bad that some systems will now tie themselves in a knot to protect you from raining on Miyazaki’s parade – for example ChatGPT is particularly bad. I asked it to re-render a photo of myself “in a traditional 1960s Japanese anime style” and it started thrashing around saying its content filters did not allow that, but maybe it could do something in some other style…? So I asked it to do some Soviet propaganda-style art and it said it couldn’t do that, either. This will be resolved with some fine-tuned training in a future version.
By the way, the underlying image creation engine in ChatGPT is still Dall-E, it’s just been substantially upgraded and now it does really nice work. As you know, I’ve been posting work from Midjourney for a while, but I finally dropped my Midjourney subscription after it got prudish with me one time too many. But, it’s nice to have a system for creating stuff, where I don’t need the whole infrastructure fired up and blowing sparks and steam. A command line and a “go” button is a great way of exploring the weird world we live in, visually.

The passive aggressive busker, Krea AI
So let me plug Krea for you. If you’re into producing short videos, Kling may be slightly better, but they’re leapfrogging eachother. Midjourney, as an image-maker solely doesn’t do it (whatever it is) for me any more. There are a lot of reasons I’d like to encourage you to check out Krea, so let me just free associate a bit.
Chat Mode: This is the “new thing” last week for AI image generation. The idea is that you use a chat AI as a front-end for the generation function, and can build on the image contextually. Let’s say, for example, that I want the AI to help me generate a few sketches of an object that might become a cool cane-topper.
Me: I am developing an object to manufacture as a cane-topper. It will be sand cast, which means there should be a minimum of undercuts and no through holes. If you reach a spot where you’d do a through-hole, fill the object so we’re just looking at the surface geometry. The object we’re going to be making is the skull of a sabre-toothed squirrel.
AI: Right, ho… (presents 3 images, sort of like Midjourney does) Actually, it repeats its idea of what it thinks you want:
“I’m creating a detailed sketch of a symmetrical sabertooth squirrel skull ornament from three sides, ensuring minimal undercuts and pierce-throughs for your bronze casting needs.”
Me: Pretty good, but can you make the teeth more extreme, and close its jaw?
etc.
The ability to correct and iterate is great. For one thing, with a classical Stable Diffusion Prompt you don’t get any feedback about the language you use. If you use a word in a way the checkpoint is not trained for, you’ll get whatever it’s trained for (why is the lady holding a shaved maine coon cat?)
Real Time Mode: This is the one that blows/blew me away. I have vague ideas, but I’d really love to know how it works – I guess it monitors prompt changes and does very quick image approximations. Anyhow, you give it a prompt (that’s standard) and then create regions on your work space and write prompts for them, too. You can move them around, rotate them, scale them, etc., and it reflects the effect of your change in realtime.
So: “Night market under a starry sky, spirits peddling wares, echoing spirited-away vibes. large lanterns”

You can see on the left that it’s possible to insert images, to specifically target a region for something, e.g.: a viking warrior. Or you can just create areas and a background and it’ll do something with it based on your prompt:

So, I changed my prompt to “an angry viking warrior is here” and it instantly flipped to something with a higher amount of viking content:

That’s because I didn’t delete the green balloon. If I change it to something else, it’ll let me adjust my composition.

One of the basic complaints about AI has been that it’s very hard to get reasonably precise compositions, or put things on things or in things. I’m not going to say that the problem is “solved” here but it’s much much much better.
Flux Model:
Krea appears, like Midjourney, to be maintaining their own high quality model. So, if you want to switch to that, you can just get a normal prompt like with Stable Diffusion, and get the best image that they can do for you given the model and a selection of styles. The busker in the subway took me less than a minute to produce. I like the fact that I don’t have to keep downloading 20gb checkpoint files and waiting 5 minutes for an image to generate.
Enhancer:
The enhancer mode isn’t particularly exciting to me, but it’s pretty cool. You hand it an image, and it tries to make it better, fix it, whatever. I just grabbed an image, which was funny because it was deliberately lit and toned to look like an old painting, and the enhancer mode sort of kind of did something. I can tell it did a lot of edge detection and sharpening on the side that it adjusted. I guess it’s fun but I’ve spent thousands of hours in Photoshop and I still can’t get my mind around letting an AI frob all the pixels I carefully positioned in an image.

Movie Mode: The movie engine is Wan, a video AI from China (oo! O Noes!) but Krea’s setup makes it easy to do, instead of literally spending an entire day downloading and setting up Wan on a desktop, like I did. The AI video engines won’t, yet, produce weird or shocking stuff, but there are people out there at this moment torturing training AIs to be able to make some pretty freaky stuff.
Just for example:
It’s pretty cool since it lets you watch the diffusion process as it runs, and you can sort of kind of see how it works. Just poking in a prompt and hitting “generate” is not going to achieve particularly great results. The way to get good results is use one of the other modes to produce a series of images that you want as keyframes, then give those to the video generator, which will try to work them in, in some way.
As an aside, I’ve been shocked recently by what garbage people are. Within a few hours of the earthquake in Myanmar, there were WAN-generated videos of buildings collapsing and streets buckling all over instagram – now that the only value of humans is their attention, people will do literally anything to get you to click on their moment of flickering pixels. I am also, I must say, really disappointed by the transparent tricks that are being played to get (almost entirely men) to follow sexy-looking AI pixels, or whatever. Apparently our brains have a center that detects jiggling boobs very accurately. I know the job market out there is pretty iffy right now, but I feel as though the OnlyFans bubble is going to burst, too. Oh, well. It’s all bubbles. Kids these days are just going to be lucky if they have a civilization to participate in, 40 years from now.
This is my prompted artistic rendering of the great tsunami that hit William’s ships at Hastings, something something mumble.
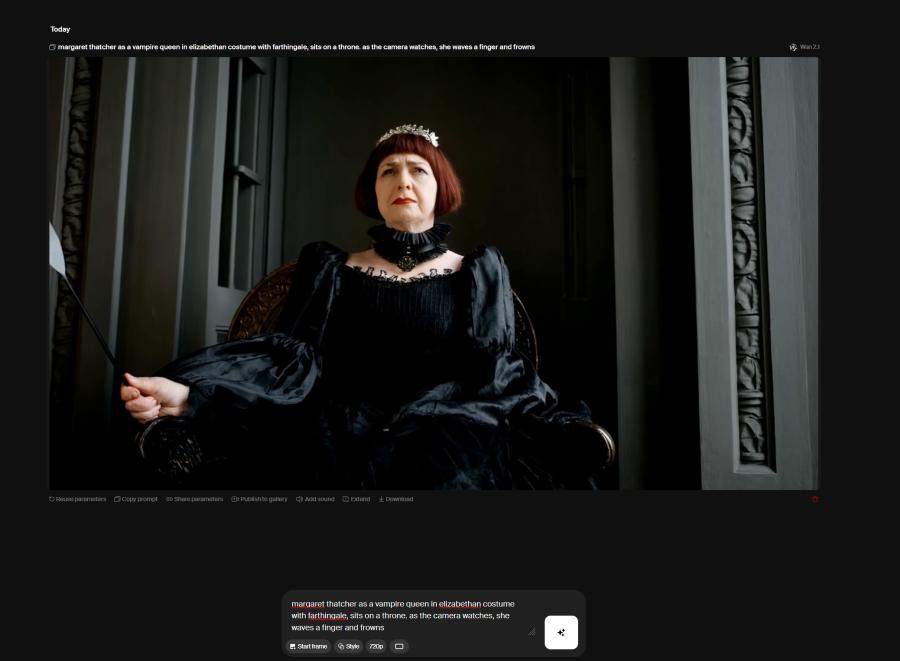
What’s a bummer is that the really deliciously weird stuff is not possible because it involves blood and Margaret Thatcher, or The Black Knight from Holy Grail or goodness knows whatever other madness. I’m pretty sure that WAN AI wouldn’t do a good job of rendering Williams knights charging a PanzerKampfWagen IV so I don’t even want to bother.
Edit: The edit mode is something Adobe started doing in Photoshop suite and now that sort of thing is everywhere. You can combine and mask existing images to form composites and the AI will fill in and repair the details. I have not bothered with it much. But, for example:
You select the area you want to fix and then put whatever you want to see in the prompt and see what happens.

OK, that’s pretty good-ish. Considering it took me exactly zero effort. It’s not perfect, of course. If I really wanted to make the image that much better I’d generate components in the generator then assemble them by pasting them together. That kind of thing is not really my cup of tea. For example if I really wanted to do a good video I’d take a good portrait of Margaret Thatcher than have it render her as a master vampire, then train a “style” based on the rendered master vampire look, and then I could do keyframes of the master vampire, and they would look quite realistic as these things go.
Well, so, that’s the state of affairs. Image processing is going huge leaps in strange new directions, as AI are becoming a key component in workflow and not just a text-to-image generator.
I’ll write more about this later, but here’s a teaser: the Chinese have released a thing called Hunyuan, which is an image to image or text to image generator that can output textured 3D models. I’m slowly integrating all the systems so I can produce weird items in Stable Diffusion, convert them to 3D models, optimize them in Blender, print them on the 3D printer I just obtained, and do sand molds and cast metal objects. The potential for mischief is high.

I’ve been doing some light machining on the metal lathe (! fear !) with some success. And I have been continuing to improve my soup-making and dumpling-making. The seedlings in my greenhouse are sprouting, so I will have cilantro and green onions soon. And, the shop is within a few paces of being completely done. As it is, it’s amazing to be able to walk in there and get right to work, everything is exactly in the right place. Sensei Bell is having a special get-together in August with a Japanese master smith and his apprentices in attendance, and we’re going to be seeing if we can make some short swords out of tamahagane. I will have to be on my best behavior for that!
The ability to add/position things on an AI-generated image is both an obvious need and an incredible improvement. It may not be at 100% yet, but that’s going to change how a lot of AI stuff is done.
Right now I see posted batches of AI work, usually 20+, of the same basic image but everyone is slightly different and the artist is not making any decision on which ones are the best to show. Or maybe they are, and are making a selection of dozens out of hundreds. The ability to position things within the AI image will give the artists a lot more creative control, and I hope we’ll see a reduction in the multiple images of the same subject because the artist will post the few images which reflect exactly what they imagined. Cool stuff.
It sounds like you are threatening to send it to a re-education camp‽
Reginald Selkirk@#2:
It sounds like you are threatening to send it to a re-education camp‽
It gets the finger count correct or it gets the hose again.