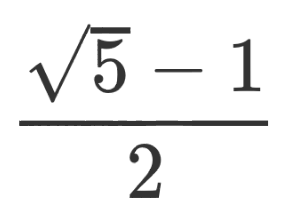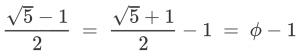Whenever anyone asks me for my favorite scientist, her name comes first.
At a time when women were considered intellectually inferior to men, Noether (pronounced NUR-ter) won the admiration of her male colleagues. She resolved a nagging puzzle in Albert Einstein’s newfound theory of gravity, the general theory of relativity. And in the process, she proved a revolutionary mathematical theorem that changed the way physicists study the universe.
It’s been a century since the July 23, 1918, unveiling of Noether’s famous theorem. Yet its importance persists today. “That theorem has been a guiding star to 20th and 21st century physics,” says theoretical physicist Frank Wilczek of MIT. […]
Although most people have never heard of Noether, physicists sing her theorem’s praises. The theorem is “pervasive in everything we do,” says theoretical physicist Ruth Gregory of Durham University in England. Gregory, who has lectured on the importance of Noether’s work, studies gravity, a field in which Noether’s legacy looms large.
And as luck would have it, today was the day she was born. So read up on why she’s such a critical figure, and use it as an excuse to remember other important women in science.