A typical AI model like GPT-3 now contains beelyuns (billions) of decision-points – it’s a huge probability map of all of the potential answers that have generally been given before.
I’m still fascinated by the technology, though I see its many (current) flaws. What’s going to happen is that it’ll just get better and better. Remember what happened to machine translation? For a long time, it was a joke and now suddenly (in geologic time) it’s usable. It’s still not perfect but you can enjoy a movie with real-time subtitle translations in Latin, if you want.
One of the things I have been noodling over is the question of the degree to which AI models are being used to write what passes for “journalism” nowadays. I don’t expect literature as art, but I’ve run across articles and small postings that really do read as though someone told an AI: “give me a top 10 listicle of the best things about sliced bread.” Or something like that. Anyhow, I was thinking about that and watching some really excellent covers of some Sisters of Mercy songs (by the amazing Tobias Forsner) [forsner] and it occurred to me to ask one of GPT-3’s children: “write the lyrics for an unpublished song by the sisters of mercy”
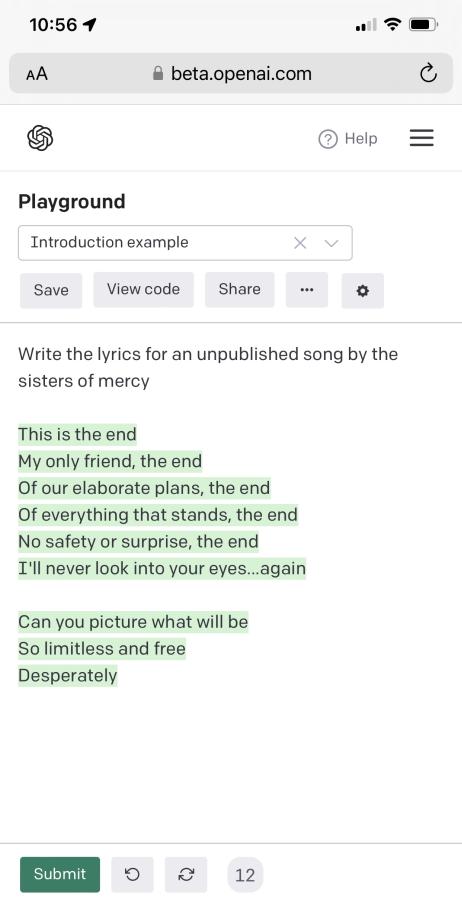
Whoah, those are some heavy-duty lyrics. They remind me of a song by The Doors. In fact, it is a song by The Doors, and one of my life-long favorites.
Questions remain: what if I didn’t recognize it, because I am an uncultured barbarian, and I post “hey this is my new song, check it out!” and get a lawsuit from Warner/EMI Records. Or, more likely, some social media site’s AI would recognize it as a copyright violation and take it down, much to my surprised incomprehension. Instead, I’m left wondering what roll of the AI’s dice took it down a path where “The End” is the first thing it serves up. I approve, but I don’t. Somewhere in that billion nodal points of probability, is encoded “The End.” Is it word for word the right lyrics? I don’t know.
I fed it the same query a few minutes later and got something that looked like The Sisters of Monkees:
Hey we’re the Sisters of Mercy,
hey hey hey hey,
hey hey hey hey
That’s … actually kind of realistic, which makes me again confront how it is that I can be fond of such mediocre music. But I am.
This is: “an AI bot that has just plagiarized shakespeare and feels haunted by the ghost of the bard, detailed colors blue and gray 3d realistic.”

Most of the good images use user-provided references to “steer” the AI in the right direction as “hints.” It’s a pretty neat process, which can allow some continuity between images – say I’ve developed a comic book character and I want the AI to render the character the same way in multiple frames. That’s a pretty neat capability and it’s something I’d expect a decent cartoonist to be able to do. What you do is provide a link to the image by quoting it to the AI and then linking the URL in it.
This was my prompt:
a cartoon version of sam harris writing a blog entry. style black and white with clean lines, cartoonish, exaggerated
and this is what I got:

It looks like Sam tried a teleporter machine and there was a fly in it with him, or something.
Mysteriously it does not seem to be working. One of the things I hate about using these AI frameworks is that the programmers developing them are constantly fiddling with stuff. It’s all fiddling.

Imagine a cartoon version of Jordan Peterson that also looks like rasputin. style black and white with clean lines, cartoonish, exaggerated

Try this:
https://isfdb.org/cgi-bin/title.cgi?1533471
Included in:
https://en.wikipedia.org/wiki/The_Year%27s_Best_Science_Fiction:_Thirtieth_Annual_Collection
(I’ve been getting those compilations for a while and am seriously pissed off that the guy went and died so they’ll be no more.)
Also, who owns the copyright to AI-generated content?
Dunc, ask an easy question, I can give an answer.
AI created content belongs to the owner of the AI.
Until the AI becomes senteint, then it will be disputed for a long time.
If the copyright belongs to the owner, does the responsibility for plagiarism go along with it?
The Software Freedom Conservatory wrote about this awhile back:
sfconservancy (dot) org/blog/2022/feb/03/github-copilot-copyleft-gpl/
Rick and I were watching some gameshow on Hulu and Grammarly was advertising that it now contains a plagiarism detector. So they will use an AI to check an AI to make sure it doesn’t copy an AI.
Its AIs all the way down.
Can an AI plagiarize so well an AI can’t tell?
If someone has invested an appreciable amount of their own time and money in buying or making the machine, its software and/or training data, and they issued the request that generated the work, there definitely is a case to be made for them to be regarded as its creator — and responsible for securing permission to use other people’s material.
But in the case of an AI which is made available for use by the general public, and responsibilities are divided with no obvious bright lines as to who was responsible for how much, I think the simplest and fairest solution would be to say that no copyright inheres in any work it generates. Such works, if original, should go straight to the Public Domain. And if the AI is not smart enough to attribute reused material correctly, it is faulty.
After all, the real purpose of copyright is to encourage contribution to the Public Domain; every copyrighted work will eventually pass to the Public Domain, one day. And everything is a lot quicker when you use a computer …..
Apparently some image-sharing sites are getting so buried in AI-generated images they are trying to ban them. Sort of like trying to push the ocean back with one’s hands.
“Until the AI becomes senteint, then it will be disputed for a long time.”
Non-human sentient creatures can’t have copyright. This was established with the rights of animal selfies. It’s owned by the person who owns the camera, or in this case the AI.
And if that isn’t some people’s goal with these tools I’ll eat my hat.
@dangerousbeans, #9: There should be no right of exclusivity in those images. They should belong to the Public Domain from their creation.
Goes to the definition of “sentient”. While some people would consider e.g. a dog to be “sentient” (able to perceive or feel things) I think what was meant here was something more like “conscious”. Arguably AIs are already sentient, in that they are unarguably able to perceive inputs (otherwise they’d not respond), and whether they can be said to “feel” things starts getting into definitions as well.
I think responsibility for plagiarism rests clearly and unarguably NOT with the owner of the AI – who may not even be a single person – but rather with the person who caused the AI to create the work at issue. AIs are not just spontaneously generating stuff without being on some level told to. Whoever’s telling them to – that’s the person with the responsibility to not plagiarise. Seems pretty simple to me.
Call me back when an AI that has had NO directing input gets bored and decides, entirely of its own volition, to start making art from other people’s stuff. I think we’ll have larger problems when they develop that degree of autonomy, because I don’t think making art will be top of their priority list…
sonofrojblake @ #11: I think the problem here is not the (reasonably) proximate cause of the AI producing the work, namely the user requesting it. The AI has processed and integrated into its model a vast number of works, some copyrighted, some not. When it produces output, it’s based in varying proportions on some of these works — sometimes, as Marcus found out, verbatim.
This is not much different from how humans work sometimes, especially with music, from what I understand. Often what seems like a new melody turns out to be something the composer has heard at some point and stuck with them. This can be a genuine coincidence, but most of the time it’s their memory eventually coming up with a fragment of music, but not the context. This is a thorny problem for musicians, and the line between original and derivative has been debated a lot (sometimes in court).
The problem here is that the AI does something like this all the time: a lot of it is loose pattern-matching, which then brings up a distilled form of the training data. Where do we draw the line between derivative and original? When we give a prompt and receive an image, how do we, not having encyclopaedic knowledge of art, even find out where the “inspiration” came from?
cvoinescu:
But we were supposed to be talking about copyright law…. We’re all acting like this has to do with some kind of principled logical argumentation, convincing tangible evidence, “originality” (as if anyone can say what that even means or when it ever happens), and so forth.
The fact is, if rich assholes can do little or no work to get even more money they don’t need by exploiting other people, then that’s the only thing you need to know about it. Because if that’s the case, they will do everything in their power (which is considerable) to ensure that they can do so “legally” and that ordinary people can’t.
You reminded me of this part from Theft! A history of Music.* As one of the characters points out, at one time the whole music publishing industry was built on people (freely) performing works.
This was just marketing — the public needed to hear it first, if they were going to be enticed into buying the precious sheet music. Likewise, those customers can now perform it without harassment or legal consequences, because you just sold them the means to do so. This was at least implicitly the deal that had been struck back then, although it’s almost unrecognizable now.
But soon enough, player piano rolls and audio recording formats gave rise to “mechanical” rights, since that was no longer just a way to market the product (the published notation) because it was now the primary and most profitable product to sell to the masses (the published recording).
There was no doubt whatsoever, but it also simply did not matter, that the people who would play the tunes in the shops were not performing their own works or necessarily doing anything “original” with their interpretation for it. It was just a non-issue. As a publisher, you were not asking such people for a cut because you paid them to do this: it was their job to help you sell the product.
Things are very different now, obviously. If there is a way to make money from these things, somebody will want all of that money for themselves. The laws will catch up with them eventually, and until that happens, those people will have no problem breaking and bending the laws that we currently have. To the extent that those laws are even relevant to something like AI-generated art, they won’t be by the time the case gets to court and meets a conservative judge.
*A (free online) graphic novel (main page here). It’s a bit long and strange at times, but worth a recommendation for those interested in the topic.
I recently saw some stupid-looking clickbait articles titled “This AI drew a picture of Hell!” and “This [other?] AI has drawn a picture of Heaven!” Neither thumbnail illustration looked like anything that hadn’t been done before. My guess is that the AI(s) in question just searched the Toobz for pre-existing paintings of Heaven and Hell, and just sort of mashed them together to get a composite image of each place. Most of the original human artists are probably dead, so there won’t be any copyright problems…
Wow, which AI generator did you use for the robot? That thing looks kind of scary good.
Raging Bee @ #14: My guess is that the AI(s) in question just searched the Toobz for pre-existing paintings of Heaven and Hell, and just sort of mashed them together to get a composite image of each place.
You’re not far off. The AI is fed a chunk of the Toobz at the beginning, and it mashes the images together in their big “model”, while trying to guess which feature of each image is salient to the associated description. This takes a long time on a large number of processors, so it’s often done only once. Then, when you request something, you get a mash-up of whatever features your query tickles within the AI’s model. (There are layers that do different things, and some parts of the process pass through the network multiple times to allow the AI to settle on something more-or-less coherent, but this is not far off.)
One of the things that I’ve wondered, though, is… who owns the copyright on the training data? And how much of a case could one make that what the AI is doing is derivative work because your work was fed in as part of the training data against your wishes and possibly illegally?
How long until we see (assuming we haven’t already) licences with terms that prohibit the use of a work of art as AI training data?
Not sure how such terms would be enforced…
@Holms: Midjourney
Terms could only be enforced if the training data is made public. Which they obviously won’t do.
Clearly the problem is capitalism
How is this different from how human artists learn to produce art?
Copyright is not necessarily held by the creator of a work, if a company hires a creator to write, draw, paint, etc., the copyright is generally owned by the company. So sentience is not really a factor in determining copyright, the terms of contract are.
For these publicly-available image-generating AI’s, I would look into their terms of service. They may have already stated that they own the copyright for any results generated with their AI.
Ultimately, the AI is a tool, a very sophisticated tool but only a tool to help a creator generate artwork. Even if the AI becomes sentient, it remains a tool. Just like a human creator hired to create a new logo for Disney; Disney hired that creator and owns the copyright. That person may draw on their memory of thousands or more of previous artwork, just like the AI does.
So, as I see it, copyright would land in the following areas:
1. If the AI is hired to a company to use, the contract should and probably would specify who gains the copyright of the results of the AI. If not explicitly specified in a contract, I expect the hiring company would by default get the copyright to the creative work. This would be also true if an individual contracted the company who created the AI for use of that AI. The individual would own the copyright.
2. If the AI is publicly available and the terms of service for public use indicate that all content generated by the AI is copyright to the company who created the AI, that really settles it. Legally, the copyright to the images generated by the AI is owned by the company which produced the AI.
3. If the AI is publicly available, and there are no terms of service indicating that all content generated by the AI is owned by the company who created the AI, the person putting in the parameters, using the AI as a tool to create an image they desire, should own the copyright. I admit it’s less clear then the previous examples, but if the AI is seen as a tool to facilitate creativity then the person entering the parameters is the person being creative. This is the only situation which might change if the AI becomes sentient. But that would add an additional complexity. If the AI is sentient is it an employee of the company who created it? In which case the company would own the copyright. Or is it an independent agent which the company needs to explicitly hire? Then the AI would own the copyright unless hired by the company.
My gut feeling, without looking, is that the terms or service for the publicly available AI image generating programs is that the company providing the AI owns the copyright. Which they won’t care about unless someone tries to profit from the use of their publicly-available AI, in which case they will probably rely on a violation of the terms of service to start negotiations.
However, Marcus raises a very good point about plagiarism. As I understand it, the owner of the copyright is responsible to avoid plagiarism. And the company who’s work is being plagiarized is responsible for defending their intellectual property. That is, if company A creates a logo which is clearly a plagiarized version of company B’s, company A is responsible to avoid using it against the threat of legal action from company B. Ignorance is not an excuse for company A to generate a plagiarized form of company B’s logo, but company B has to complain about it if it happens. In the first case, where an AI is hired by another company to generate a creative work, the company who hired the work is responsible to check for plagiarism.
In the third case, where the person who used the AI as a tool without restrictions gains the copyright, that person would also be responsible for plagiarism.
But in the second case, where the terms of service state that the creators of the AI retain the copyright to all creative works generated by the AI (unless explicitly sold), but are providing the use of the AI free to the public, there is a problem. The argument the creators of the AI will make is that they are not responsible for the results of the public use of the AI, and so are not responsible for any plagiarism, but at the same time they hold copyright. Much as a lot of social media companies say they own the copyright of anything published on their social media, but are not responsible for any plagiarism.
I don’t know who well that argument will hold up legally over the long term. For a company to claim it retains complete ownership over property (copyright), but bears no responsibility for illegal use of that property (plagiarism), is not a tenable position. I know that the social media companies have argued that they cannot effectively police their property, but eventually I suspect the courts will get tired of this argument and say that they either have to figure out a way to do so, or they no longer have full ownership. If I build dykes in Holland to expand my land, the company which made the shovel I used shouldn’t have a claim on it.
If I build dykes in Holland to expand my land, the company which made the shovel I used shouldn’t have a claim on it.
Their “claim” consists of the price you paid for the shovel. If they wanted more from you, they should have charged you a higher price, on the assumption that you’d think of it as an investment, which you’d get back when you used the shovel to do whatever you needed to do to make your land more profitable. By the same logic, if an AI’s owners want to profit from material created by their AI, they should charge up front for its services, instead of offering it for free and then screaming about their copyright and saying they still own what they made for others free of charge.
Ursula Vernon, AKA T. Kingfisher, did a little graphic thing using, as it says, Midjourney, mostly for the buildings and backgrounds.
https://www.tor.com/2022/09/14/ursula-vernon-midjourney-a-different-aftermath-comic/
Anything that doesn’t look like it was made by an AI was almost certainly done by her.
Her twitter feed history has some amusing experiments with Midjourney besides this, and maybe also some with DeepL?
Bleh, got by AI engines mixed up. DALL-E, not DeepL
Hello?
Yes? I’m here.
I haven’t been saying much because I feel there isn’t much I want to say. I’m doing fine, though. Been moving rocks and polishing steel.
Good.