The DMCA (Digital Millennium Copyright Act) is an odd piece of legislation; it was another centrist bit of legislation signed into law by Bill Clinton. I’m not going to say it’s bullshit because it was produced under Clinton. It’s bullshit because it’s American.
Let’s go back to the early days of the internet boom: there were businesses preparing to make huge amounts of money by carrying other people’s content: search engines, image hosting sites, print on demand services, – tons of sites that were going to carry “user-generated content” and that brought with it a problem: copyright. It escaped literally nobody’s notice that many extremely valuable “sharing” sites were built out of intellectual property that was posted in violation of the owner’s copyright. Allegedly, the original founders of Youtube promoted the site by deliberately uploading materials that violated copyright – users and visitors quickly learned it was a place where you could find stuff, and things took off. Content draws content. And a lot of people don’t understand copyright.
As a photographer who used to post images online, I was constantly having problems – several times a week, sometimes several times a day – I’d get notices from other online fans, “this guy has a gallery of your images” and I’d have to figure out how each site did its copyright discipline, then send emails and wait. Sometimes it would result in the images being taken down, but often I was just wasting my time. The DMCA changed that. But not for the better – it just looks like it might be an improvement.
It’s complicated but I’ll try to explain DMCA in a nutshell: as long as a site has a process in place for managing copyright “take down” requests in a timely manner, they are freed from liability regarding user-generated content. Seems reasonable, right? A site gets a specific format of email to a specific account (generally abuse@site…) and they don’t have to worry about getting sued as long as that happens within a specific amount of time. There is one side-effect of this: sites have no interest, in fact are discouraged from, investigating a claim – in order to be safe, they just take down the content. For sites of any significant size, that means automatically.
There’s a more subtle side-effect, and that’s that it shifts responsibility from the site’s knowing what data they are hosting, to the owner of the data having to know about any site on the great big internet that is hosting their data. And, there are many sites on the internet, right? At last approximation, 1.88 billion – and it’s a content owner’s responsibility, now, to protect their intellectuial property on 1.88 billion sites and none of the sites are responsible for a damn thing except responding in a timely manner to a DMCA request assuming it’s a site in the US. If it’s a site somewhere else, the copyright holder can pretty much go fuck themself. That’s the legalese for it. Of course, different countries have their own copyright laws, but for a small-timer to deal with filing an international lawsuit in another language and time-zone – it’s pretty much “forget it.” So the way things work out is:
- Suppose you are Disney and you employ a literal brigade of lawyers and have effectively an infinite amount of money: you can afford to use a service that uses various image-scrapers and fancy-ass content-matching algorithms to find your content, automate sending DMCA or whatever’s appropriate for whatever jurisdiction, and people pretty quickly realize that posting pornographic Star Wars edits will get them a very lawyerly “Cease and desist” and their hosting site may delete their account – or worse.
- Suppose you are some amateur photographer or artist (or blogger) and you don’t make any money doing it, and do not have an infinite amount of time and money: you can get fucked. In order to ‘protect’ your rights you would have to spend every waking hour of every day, pro bono, sending out DMCA “take down” requests and learning copyright law in every country where your content is being stolen. And it still won’t have any noticeable effect. Thanks a lot, US legislation.
If you want to understand anything about anything in the US, ask yourself first, “how does this benefit corporations and rich people?” and if that doesn’t lead you to an answer, then ask yourself, “how does this benefit white people?” (Slightly redundant since white supremacy and oligarchy overlap a fair bit) and that’s going to tell you all you need to know about DMCA: it shifted the burden of worrying about copyright off of all the huge websites that make vast fortunes off of user-generated content, and onto the little guy.
There’s another side-effect to DMCA, which law-makers were warned about, which is that DMCA effectively offers a “heckler’s veto” of sorts: someone who does not like a particular person or their content can file a fraudulent DMCA takedown, and the hosting site will immediately require the material be taken down – whether or not it’s clearly a violation or a fraudulent request – because otherwise they risk being caught outside of the “safe harbor” provision, and the only safe path for a content hoster is to stick within the safe harbor. Of course, they have provisions whereby you can challenge the takedown and re-instate the content, but once again, it’s the content creator that has to bear the brunt of the activity. But wait – it gets worse – sites that “monetize” (i.e.: can pay content providers for adding value to the site) are incentivized to make it difficult for a content provider to re-instate their content because that way they don’t have to pay the content provider. This has happened many times on Youtube, for one example: someone doesn’t like some popular content provider and files a spurious DMCA from an email address that’s hosted in Russia – the content provider’s entire account may be locked and Youtube no longer pays them for the time that the account was de-monetized or during the entire time that the content provider frantically worked to defeat the spurious takedown. Then, when everything is back up – another takedown. Frequently a content provider will “flip their shit” at the site, which then makes the ban permanent, pocketing all the money and leaving the non-contested content up. There are internet “haters” who go around trying to lock up atheists, transpeople, drag queens, and people who disagree with them politically. That’s their hobby, and damn cheap fun it is, too. The end result is a ruthless pressure to post content only for free, and only that you completely control. The site bears nearly none of the costs, the providers bear almost all of it, and the hacker’s vetoers bear none whatsoever. It’s all backwards but that’s capitalism.
I’m not a lawyer or a billionaire, unfortunately, or I’d spend a lot of money on lawyering to blow a great big hole through the situation by pushing to amend DMCA to encompass “constructive knowledge” – i.e.: I ought to be able to notify a site “this image is mine (and here is proof) and anywhere you see it being uploaded, you now have been served notice it is mine and it’s your responsibility not to host it.” That, by the way, is the situation that prevails for the big guys: does anyone who is reading this not know that Mickey Mouse belongs to Disney, Inc.? See what I mean? You have advance knowledge of Disney’s copyright. Why not require that anyone with advance knowledge of a particular copyright should not get the DMCA safe harbor provisions if they host it? Of course that would make life difficult to the content hosters. They would scream bloody murder, because it upsets their sweet little applecart, which depends, in effect, on their saying “no we have no idea who owns what so it’s not our problem.” That’s a ridiculous position to take, but DMCA is based on exactly that fake agnosticism.
Right, so why is all this relevant?
FTB recently got a DMCA takedown order forwarded down from the hosting provider, naming one of my articles as infringing on someone’s copyright. The article in question is one in which I used my own photography – and all my own arrangements of English words – it’s the one that used to describe the “how to make a delicious dish out of noodles and peanut butter and sriracha” [stderr] Naturally, after the Richard Carrier lawsuit, FTB’s legal advisors are going to be conservative so I was asked to take the content down. That doesn’t bother me, because I don’t get paid for any of this, but it ought to bother you because now you can’t get to my recipe.
Posted under “fair use” exemption
Well, that’s not strictly true, because you can still read it, in its entirety, [here] But for now I am expected to waste time on this and potentially have to worry about bringing legal liability onto FTB, because I posted a fucking recipe with my own fucking photography on a fucking website and some rando asshat on the internet decided to submit a takedown. What’s completely freaky about that, is it makes no sense at all that they would want to draw attention to themselves, but – that’s what they did.
First, and most infuriating, how did I violate the copyright of an article written September 3 with my article written August 10? I know it’s pretty simple to edit dates but for fuck’s sake that’s just stupid. But FTB’s hosting service said “take it down” and are completely – as a side-effect of the safe harbor – uninterested in reason.
Secondly, I have the originals of the images, still. I won’t post them here but here’s one of them without being edited with my usual suite of edits – I just resized it. In a rational world, all I’d have to do is respond, “Obviously the image is mine. Ask the complainant to provide a full-size unedited copy (like this: attached) and you’ll see they can’t unless they build a pretty exacting reproduction of my kitchen counter including the vintage Dualit toaster and Keurig machine.

But, see, the way the DMCA slice-o-matic game works is that the hoster can deflect all rational argument and say “We don’t adjudicate because that would bring responsibility on us. We just act.” So my job then becomes that I have to contest the takedown, which I eventually will – but in the meantime, what about our mystery gomer?
Well, I looked on their site and there are a few things. One, it’s hosted on a German web-content platform that has a notable history in the security community of never replying to abuse@… emails. And the complainant’s address is allegedly in California. Personally, I doubt they exist, but that’s – thanks to DMCA – not their problem, it’s mine. Naturally, I sent an email to their hosting service but since it’s in Germany there’s no DMCA, I just have to make threatening copyright noises. Which is, as they say, “pissing in the wind” unless you’re Disney or Warner Brothers or Netflix.
Being a curious sort, I did a bit more research on the complainant’s pages. It looks as though the “site” has been populated by some kind of “page populator” AI for some reason. I’m not sure what’s going on or what’s the point, but there are many many postings and they’re all farmed from other places. (You don’t need to check.) Here’s an example [url]
posted under “fair use” exemption
Interestingly, our guy has some kind of javascript wrapper around the pages that prevents robots from scanning them, or copy/paste, or view source, or save-as. You know, that’s how us innocent bloggers post our pages, right? We totally don’t want google to scan our content and index it, because that’s totally how websites don’t work – unless they’re some kind of scam.
But I’m patient, and I decided to do a search for the text of that first paragraph, because I suspected (being the suspicious sort that I am, right now) that maybe that content was not original to the site. And, this is what I found:
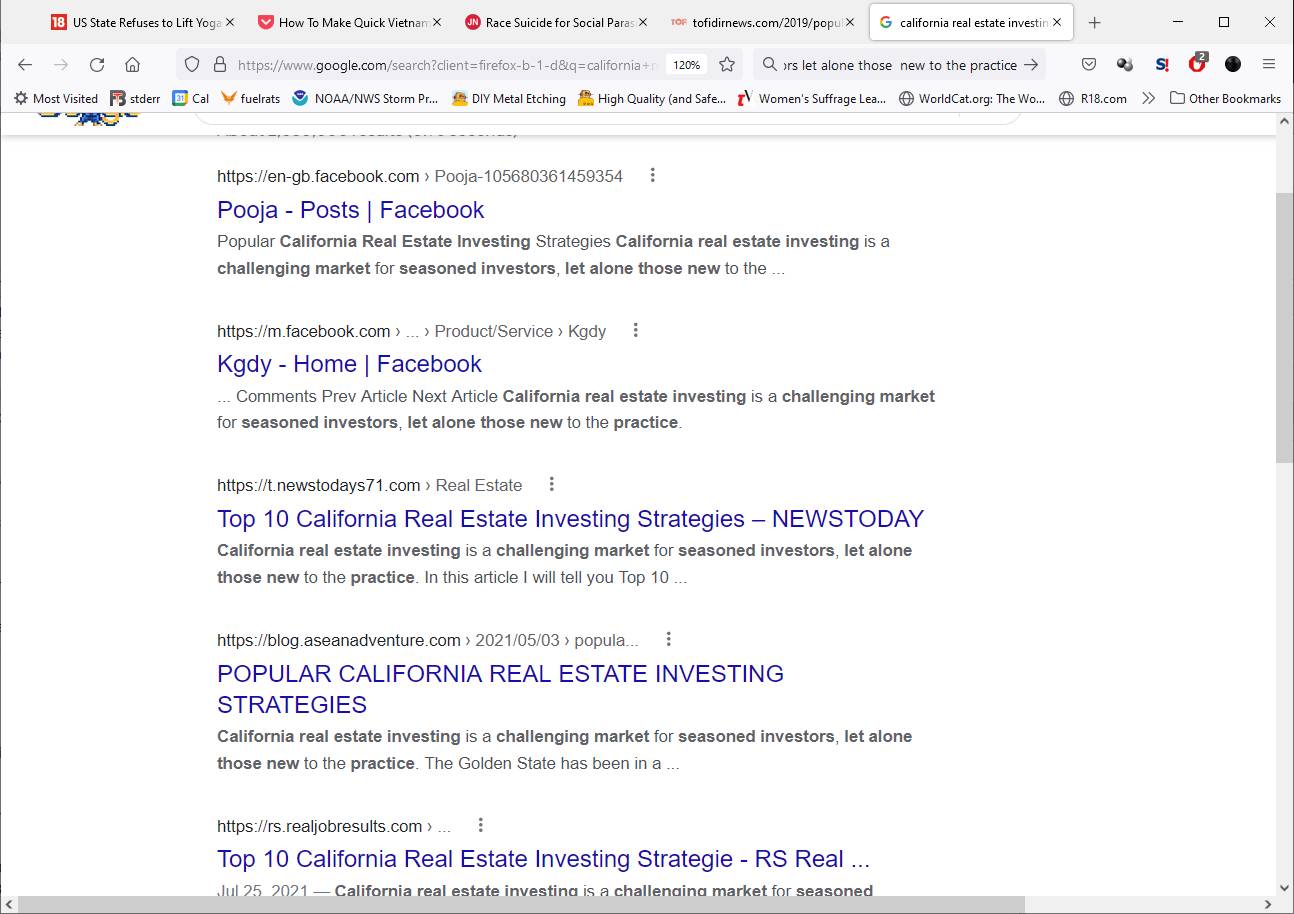
The entire “site” is populated with randomly farmed “articles” containing mishmosh of text from multiple places. One of the “articles” is titled something about automobile repair but the page text is about some internet model’s recent travel experience. It’s pretty obviously grazed by some kind of artificial ignorance tool. My guess is that it’s because some sites, like Facebook, back-check links to postings to make sure they aren’t spam, by doing spamicity checks on main and dependent pages. Makes sense, right? If you want to post spam ads, you build site that looks legit (hey look at that cool recipe for peanut butter noodles!) to the spam checker, and after a while you can post a link that is spam, hiding the spam carefully. If I were a gambling man I’d bet that the javascript wrapper around those pages gives the full content to known anti-spam scanners for the targeted websites, so if Facebook back-scans our squirrel’s site, they get content that seems legit-ish, whereas if I look at it, it’s complete crap wrapped in javascript.
I’m intermittently targeted by spammers and scammers, ever since I taught classes for USENIX on spam-blocking, and wrote an expert opinion for ICANN that “spam is definitely a security threat.” The expert opinion triggered such a raft of complaints – exclusively from spammers – that their rights were being violated, etc., completely ignoring the main point of my opinion, which was that spam is often used as a vehicle for phishing and pharming attacks, in addition to basic credit card fraud, that it would take a dishonest idiot to claim that spam was not a security problem. So, I got on the radar screen of a lot of spammers and scammers and even got an anonymous email suggesting that someone might come to my house and “sort me out.” Unfortunately, they did not get a reply since the email was from a fake address. I have a stock reply for such things which is, in effect, “I’m usually home weekdays after 5, though you can call ahead and schedule an appointment. PS – I am going to be pissed if you “no show” me after I spend an afternoon lying in my field wearing my ghillie suit waiting for you, those things are hot.”
So, I know PZ isn’t particularly impressed with the quality of his annoying correspondents – christians, muslim evolutionary biologists, people who see worms on lunar rocks, etc. – but I have a higher order of jerks to deal with. Since I retired from security, I haven’t had a problem, so it’s a bit annoying although the last 20 years of my career were a veritable flotsam of this kind of shit. My Rolodex has gotten thinned out by being away from the scene, so I no longer have the clout and the phone numbers to call folks who work for police or intelligence agencies, and many of the folks who used to owe me favors have moved on. And, should I contact the security team at Facebook? Probably not – I hate Facebook and most of them know that. Back when I was still consulting, I kept much more quiet about things like that because you never know who might approach you as a prospective client. Yes, you’re probably thinking “Oh, so Marcus didn’t used to say nasty things about the FBI? Is he getting this stuff out of his system?” Yes, and you don’t know the half of it.
Anyhow, let’s see if our gomer antes back up. Typically, they don’t – they’re usually pretty ignorant and lazy and they just go somewhere else. They’re not interested in an extended battle because it doesn’t make them any money and it might cost them a fake site or a fake account or two. Meanwhile, over here, it’s cost you a recipe.
If anything else happens I’ll post about it, but otherwise I’ll try to get my page reinstated.

The example I gave, of how a well-funded adversary could seriously fuck over websites using the law is basically the strategy Peter Thiel used against Gawker: crush someone with lawyers and everyone else changes their behavior. If fate had dropped a few hundred million dollars on me, I’d peel off a few tens of thousands and tell my lawyer “go make a project out of this guy” and see what happens, but it’s just not worth the price of the show. By the way the “go make a project out of that guy” is a quote from a CIA intelligence officer I used to know – a real cold warrior – and, seriously, it makes your blood run a bit cold to think what a completely uncontrolled intelligence agency “making a project” out of someone means. Nowadays it’s probably a generational thing; they just send a drone.
People who use these spam services sometimes seem to not have any understanding of how it works. My boyfriend has a webcomic whose content was hotlinked to a hidden page on some “bridal-partee” website, no doubt as part of a scheme they paid for to boost SEO. When he emailed the site’s owners, they seemed genuinely clueless, as well as bitchy and dense. In the end, he broke it by changing all the links on his own site.
I hope this BS doesn’t happen to me. Seems like it could have been unrelated to your history, just part of the latest spam scam. Anybody with a wordpress blog could be a target, if that’s the case.
–
I don’t know much about photography, but for various artforms there are (private, usually non-profit) organizations which collect royalties — domestically and internationally — for artists, publishers, and the like. There is a little work to be done in terms of getting a copyrightable work registered with them, but it’s certainly not as if you have to be Disney or employ an army of lawyers.
If you’re not trying to make any money from the content, then (you won’t and) that may not seem very relevant to you. I understand that you could still want some kind of protection, although it’s a little unclear what that’s supposed to entail. But if all you do is self-publish some stuff that’s practically invisible among the 1,880,000,000 other websites, it’s true that nobody else will spend a lot of time/money/resources to protect your rights on your behalf. Not even the government, which is supposed to be in the rights-protecting business if anything is…. We just don’t have it set up to do that sort of thing for the massive number of people who post random shit all day, every day. And if things do go that far, you want a nice friendly court which will make the right decisions? Good luck with that.
I’m not sure where it comes from, but a lot of people seem to treat the whole internet like it’s an honor system (despite all the dishonorable people around them), and they’re shocked that Youtube and so forth are too busy finding new ways to make money off of them. Just please … everybody stop asking for help from Youtube and things of that ilk. It won’t do that, and we simply shouldn’t be turning to them in the first place. But over and over again, we keep asking them to “somehow” figure out a solution for IP (and ways to destroy it), privacy (and ways to violate it), first amendment freedoms (and ways to suppress them), fact-checking (and ways to spread the bullshit we like), and on and on. Many people just seem to have a lot of trouble understanding that we don’t need (and it won’t help) to have more private governments ruling over us, instead of the regular public government which makes the actual laws.
Wow. That’s gotta be frustrating as fuck.
Grr.
—
Worst thing is, it doesn’t seem malicious — just random.
Presumably, had you written “This is something I, Marcus Ranum, invented…”, nothing would have changed regarding your provider’s disinterest.
My experience with DMCA — granted, a few years back — has been a bit different.
I found a couple of images of mine on a German site that sold similar products and did not want to put in the time to take their own photos. I contacted them about it, and they ignored my emails. They were hosted in the US, so I sent a DMCA takedown request to their hosting provider. They responded quickly, telling me that my site was not hosted by them so they could not do anything. I told them they got it backwards, it was the other site that was infringing, and sent them a full-resolution copy of one of the offending images. They took down the entire site. It came back a few days later without the offending images. The owner then replied to my very first email, saying that, since the design of the products I sold was open-source, he had assumed the images on my site were fair game too. I explained that the entire site, including the images, was copyrighted, and had a valid copyright notice on each page, fairly hard to miss — and that the Creative Commons license for the design was one of the “NC” ones anyway, so he was doubly in the wrong. Also, there was a contact form link on every page, so he could have just asked, or at least not ignored me when I pointed out his mistake. He said that even if I may have been right, I was wrong to make such a fuss about only a few images. I don’t remember whether the conversation continued beyond that; I may have told him he was missing the point.
What I want to say is that, for me, the DMCA process had a human in the loop, who asked for proof, and seemed reasonable. But I’m sure YouTube and Facebook and the others made their own discriminatory and arbitrary dog’s dinner out of it — not out of outright malice, obviously, but to save themselves some money. Carnegie would have approved!
Are they amenable to actual evidence that something fraudulent is going on?
The entire original article is available in the web archive:
https://web.archive.org/web/20210812062422/https://proxy.freethought.online/stderr/2021/08/10/a-really-easy-piece/
I grabbed the original images from there (noodles-{1..4}).jpg), and looked at the metadata. There’s plenty of tools to see image metadata; I used ExifTool.
noodles-1.jpg has the following:
Software : Jane Lens and Ina's 1982 Film
Modify Date : 2021:08:10 13:59:11
Artist : mjr
Copyright : mjr
Exif Version : 0221
Date/Time Original : 2021:08:10 13:59:11
Create Date : 2021:08:10 13:59:12
Copyright Notice : mjr
By-line : mjr
Lots of info tags snipped, including the GPS location and altitude (you are 447.6m above sea level).
Meanwhile, the ripoff artist changed the file name to “noodles-1-768×768-1.jpg”, with no EXIF metadata for the creation. There is file modification time, though.
File Modification Date/Time : 2021:08:17 05:17:09-04:00
File Access Date/Time : 2021:08:29 19:05:33-04:00
File Inode Change Date/Time : 2021:08:29 19:05:33-04:00
File Permissions : -rw-rw-r--
File Type : JPEG
File Type Extension : jpg
MIME Type : image/jpeg
JFIF Version : 1.01
Resolution Unit : inches
X Resolution : 96
Y Resolution : 96
Comment : CREATOR: gd-jpeg v1.0 (using IJG JPEG v80), quality = 82.
Image Width : 768
Image Height : 768
Hm.
While the source of the page certainly looks like it was “properly” backdated to 2019, I note that there is a line in there that matches the 2021-08-17 date in the image:
<meta itemprop="datePublished" content="2019-09-03T08:50:51+00:00">
<meta itemprop="dateModified" content="2021-08-17T09:19:34+00:00">
Would that help? Dunno. The same tools that let you check the metadata allow you to change it.
I note that WHOIS says that the domain didn’t even exist in 2019:
Domain Name: TOFIDIRNEWS.COM
Registry Domain ID: 2581056701_DOMAIN_COM-VRSN
Registrar WHOIS Server: whois.porkbun.com
Registrar URL: http://www.porkbun.com
Updated Date: 2020-12-27 07:29:15
Created Date: 2020-12-27 07:29:14
Hm. Looks like they don’t plan to be around long.
Registrar Registration Expiration Date: 2021-12-27 07:29:14I know that this is article is venting frustration about what happened but what would your solution be?
I know of only one thing and that is to put up actual penalties for making false claims and overly broad claims (like Universal Music Group claiming copyright on shots of the moon). But that would slow things down, and cost a (possibly significant) monetary investment upfront, as well for the non behemoths since the first step would be a verification of having (legal) representation inside the US and the willingness to put up the monetary part of the penalty in escrow.
This change would also be fought tooth and nail by the behemoths since it would require actual vetting of claims before firing them of and not the lets dump half the site on the internet in the next claim approach. Because as it stands they do not have to vet their claims at all (Google claims to reject around 99.95% of the automated DMCA notices received by their trusted copyright removal program simply because the links provided are not in their database at all or funky stuff like 127.0.0.1 or the addresses reserved for intranets)
So… can you remove the article to satisfy the web hoster, then repost the content later under a different URL? It seems unlikely the false complainant would file a second time.
@Who Cares
Random thought that literally just popped into my head. Part of the problem is the lack of punishment for false reports. However, part of the problem is also lack of punishment for the genuine offenders most of the time except for a stern warning to not do it again. Instead, we put most of the responsibility onto the hosting platform. Instead, could we move more of the responsibility to the two individuals – the supposed copyright owner and the supposed copyright violator? I don’t know how to do that though. It does remind me a lot that I hate how governments fine corporations in place of filing criminal charges against leaders of the corporation when criminal charges could be brought. I see a lot of parallels here.
I was thinking something like make the DMCA reporter have to include their identity and contact information which is automatically passed on to the accused to allow the accused to take counter legal action for harassment for false reports.
Maybe an obligation to try to identify and sue the accused copyright violator before any legal vulnerability falls onto the content hoster.
However, the anonymity of the internet makes this difficult, and multiple national jurisdictions makes this harder still.
I’m just rambling. I would also like to know what Marcus thinks.
Different but related. A motive-less theft.
For much of this century I maintained a vanity site hosting my literary products, full text of a couple of books I published in the 1980s and a couple of screenplays. Around 2017 I decided it wasn’t worth $25/year to expose the Internet to my brilliance, so I let the domain lapse. A couple of weeks later, curious to see if it had gone away yet, I googled it and to my surprise found that the domain name had been renewed by someone else and was back, with all my content. After dithering a while I contacted a lawyer specializing in IP and for a modest fee she wrote a nasty letter, and shortly the domain disappeared. I assumed that was that but…
…preparing to write this note I tested the domain, and it’s back, baby. Some of the content has turned into 404 pages. Nothing has been added, and as far as I can tell, there are no ads or malware injected. I don’t understand the motive for this theft; I can’t imagine what the person gains from paying the domain reg. fee year after year just to keep my old stuff alive.
Who Cares@#8:
I know that this is article is venting frustration about what happened but what would your solution be?
Obviously, there are no solutions.
But, the question is a matter of moving around the presumed burden of compliance. In the current situation the cooperative citizen bears almost 100% of the burden and the criminal none. The hoster/aggregator has also managed to shift the burden off onto the cooperative citizen. Obviously, as I pointed out, that was done for money and by money – DMCA happened the way it did because of intensive industry lobbying.
Any reasonable solution would be to re-balance the burden. Obviously, we’d want the majority of the burden to fall on the would-be criminal, but secondly on the aggregator. After all, it’s the aggregator that is making money off the stolen content – it’s not unreasonable to ask them to jump through a few hoops in order to do that. Of course they’d scream blood blue murder: their whole business model is based on being able to safely and legally carry content that violates copyright.
Some options: give the hosting providers no safe harbor if they do not do diligence to identify content posters, and require them to track content posters that violate copyright repeatedly and terminate their accounts. One of the problems with the current arrangement is that the content providers (as I said in the OP) can treat individual pieces as just that: “oh THAT picture is a copyright violation, well we’ll take it down but we’re not going to look at the rest of your gallery.” That’s bullshit. Obviously they don’t want to close an entire account because they value the copyright-violating content that they can continue to sell banner ads on but they ought to enforce a “3 strikes and you’re out” policy on cheaters – if I send in a takedown on someone’s gallery and it contains 3 of my copyrighted works then the burden of proving they produced the content should shift to the person who posted the gallery.
The safe harbor on identity could also be established with a bond. I’ve suggested this to several sites and generally the reaction is a horrified recoil but, if you think about it, that’s the point: when you sign up for the site, you put down $500 to activate your account’s posting privileges. That money is kept in escrow and accumulates interest. When you shut your account down, you get the money back. But, if we shut your account down because you violated copyright or TOS, you lose the money. That shifts the burden of establishing and maintaining identity to the user, away from the victim and the content aggregator. I suggested this to some of the folks I used to know at Google’s Gmail management team – establish a “known user” program based on the escrow system, and re-weight spamicity statistics based on that. There are people (like me) who will never send spam or violate someone’s copyright, and I’d have nothing to fear. Of course, hecklers could post false claims, but only claims that are backed with the escrow would get listened to, and someone posting a false claim loses their escrow. Simple. Anonymity could be done by putting up a larger bond in escrow, and using some additional authentication. [That brings up the whole “government-issued fake ID” proposal I made back in 2004, which made everyone recoil in horror]
The other key to the problem is what I teased with the bit about “constructive knowledge” – we should require that if a content provider gets a takedown for one piece of content belonging to me, they should be responsible for taking down all of them, since I have just informed them of the violation. They should not be allowed to continue to violate copyright on that specific piece of content thereafter, without being liable themselves. That would mean some technical infrastructure, sure – an image database of image engrams and a legitimate best-effort to match them. That’s what Youtube does now with music, fairly successfully: they have trained some neural networks with tons of copyrighted music and they look for strong matches in uploaded videos’ audio tracks. If someone wants to run a multi-hundred-million-dollar website full of content they damn well can do some technological response and not just wave their hands and say “safe harbor.” Would this have a cooling effect? Hell no – it’d be a tiny infrastructure cost for the aggregators and for a small provider it’d have no effect. Suppose on my ranum.com website, which has about 1200 images total on it, if someone sends me a copyright violation letter, I know all the images on the site and I’ll take anything down. Basically, that’s the problem, the content providers have been indemnified against having to know anything about their content. That’s bullshit because they know enough about it to track what’s popular, what’s not, and what’s monetized and how many people look at it. If you got an honest answer from Youtube they’d say they could use copyright analysis as a way of getting out of having to pay “monetization” to people violating the TOS. That would take the financial incentive to post copyright violations away, more or less instantly. Then shut down the whole account (as I mentioned in the OP) and force the account holder to demonstrate that they own the original content, which is not hard if the copyright holder is serious about making content.
We have huge volumes of spam and scam on the internet, because the internet is tilted toward making it easy for content aggregators to re-push spam and scam. Some massive percentage of the traffic on the internet is spam and scam. It’s absurd. People talk about “Facebook needs to do something about bot farms” – the rather obvious thing is: “if you want to post content and have it appear instantly without review then you need an account in good standing and you need to back it with solid identity and some cash.” If you post shit that is a bunch of lies, we keep your money and shutter your identity.
This is probably a topic for a whole posting, but the real issue (IMO) is that identity is disposable. If identities are valuable [back to my “Government Issued Fake ID” proposal] then there’s a disincentive to “burn” an identity. Here’s a simple example: [email protected] has never been an email address flagged by any provider as having sent spam. Not in over 20 years. That ought to be a factor in spamicity calculations. Maintaining an identity long-term is valuable and providers ought to request a bond from identities that are created and immediately post content or send messages. Track a person’s history of posting over time. I do that, here, manually – I know which of the commenters here is OK and when a new commenter appears and posts an ad, they disappear forever. The commentariat here is curated and therefore valuable. Facebook and Twitter have a problem that their commentariat is not worth shit.
GerrardOfTitanServer@#10:
I was thinking something like make the DMCA reporter have to include their identity and contact information which is automatically passed on to the accused to allow the accused to take counter legal action for harassment for false reports.
That’s in DMCA, but it’s minimal and exists only to favor the big aggregators, as usual.
The DMCA takedown that I got for my page includes a name, email, and address in California, and a phone number. The address does not exist and the phone number rang until someone answered and immediately hung up.
Because the internet has no value to identity we continue to have problems with disposable identities. IMO there should be tiers of identity value and those tiers could be backed with money, time-in-service, or other techniques. Doing it right would mean maintaining identity pools [see “Government Issued Fake ID”] and that would be a profit center for companies doing it right. What if a “registered Twitter ID” had value? Would people risk their valued ID by posting lies that could get their ID shuttered?
Owlmirror@#5:
Are they amenable to actual evidence that something fraudulent is going on?
No.
Mostly I’m dealing with robots. On all sides, robots – I’m pretty sure the guy whose site is populated with stolen crap is using some kind of content-grazing tool. And FTB’s hosting provider (which is huge) is using some kind of robot work-flow management system for processing the complaint. Nowhere is any brain-effort being expended.
I’m pretty sure there have been scam emails that used one of my e-mail addresses as the “From” (the E-mail body has a different address to contact). It’s obviously not actually from me, when the headers are examined. It’s not common, but it does happen. But maybe that’s what you mean; no-one should flag you just because a scammer used your e-mail as a mask.
Owlmirror@#15:
But maybe that’s what you mean; no-one should flag you just because a scammer used your e-mail as a mask.
Yes, that’s the thing.
Unfortunately, a lot of this stuff would entail having a workable framework for identity – so that emails could be effectively “signed” by the sender. That would involve a working certificate registry, etc.Those are not easy problems at all. Unfortunately, when the original digital certificate hierarchy was being designed, there was so much potential value in it, that all the pigs charged the trough and knocked it over. The standards pukes decided on X.509 because there were some strong advocates of that (as opposed to light XML or even attribute value pairs) so the certificates are a pain to check and there were numerous security flaws in the parsers. The whole thing was a ginormous clusterfuck because it was left to simultaneously those who cared passionately (not always the right people) and those who had a vested interest in “something, anything we can monetize” It all needs to be scrapped and started over.
It turns out that these things are hard. So, instead what do we have? Credit cards and cell phones, which are respectively a password and a dongle, from a security standpoint. Leveraging the credit card companies for identity would have been too rational. But, again, nobody wanted to give the credit bureaus control over identity, either. The end result is that Google is a form of federated identity that is not connected to Microsoft Office/365 which is another form of federated identity which is not connected to Facebook and Twitter – because all of those entities want to control their respective user-bases.
Owlmirror@#15:
I’m pretty sure there have been scam emails that used one of my e-mail addresses as the “From” (the E-mail body has a different address to contact).
That was a first-generation anti-spam dodge. The assumption was the owlmirror@whatever’s spam blocker will tend to let through email addressed to or from owlmirror@whatever – so let’s just make the envelope say owlmirror@whatever and have a different reply-to: address. That worked pretty well for a while.
What sucks major butt about all of this is that I come from the UUCP and JNET days, when email was not a guaranteed reliable service like it was, briefly, in the early 90s. But now, because of probability-based spam filters, there is a probability that our emails won’t get through. It’s right back to the UUCP days, where you had to know to avoid a path through ihnp4 because their server queue was unreliable and dropped messages.Basically if I reply to a user @gmail.com there is about a 20% chance Google will trash the message because the hosting service I use has had spammers in the past and so has Verizon’s edge cloud.
Spam blockers should be based on identity reputation not reputation of some IP address, but that’s hard. Again, identity would have to have some persistent value, which it doesn’t because the premise of Facebook etc is “everyone can have as many identities as they want!” because their content model is “everyone can post whatever they want.” The two goals are opposed: you can’t control content for crap while there are enterprises that entire content model is “all the crap that you can push, you get!”
Another thing: some gigantic amount of all internet traffic and server load is junk. If we had a verified identity system and people didn’t propagate stuff from unverifiable identities, the internet would be, literally, 10 times faster – at least. It’d be like a massive, free, infrastructure upgrade.
Marcus
What you say about identity – it really hits home. I agree.
Note that some other countries do it. For example, in South Korea, most / all of your online accounts are tied to their equivalent of a social security number. The online accounts can still be anonymous, but the hosting provider is required to associate the account name with a social security number. For example, to play League Of Legends online, one needs to create an account with Riot Korea, and to do that, one needs a valid Korean social security number.
I also want to bring up another example that you can relate to. Back when I played CS:GO a little bit, there were a lot of cheaters. Sometimes cheaters would get banned, but the problem is that Valve’s business model benefits from the cheaters. Cheaters buy a new account, play for a while, get banned, and then they have to buy a new account, which means more money going to Valve. Valve could take stronger steps like banning credit card numbers, street addresses, etc., but as far as I know, they don’t (except for pros).
I don’t know if I like where this conversation is going. On the one hand, internet anonymity is really powerful in a good way for society. No one can doubt that it comes with extremely large benefits. However, as we see here, it also comes with extremely large downsides.
Going to broader topics, part of the problem of misinformation on social media is the lack of personal accountability for those who spread such things, which is partially (but not wholly) because of anonymity. I sometimes worry that the internet is actually more damaging to free society than helpful, and I sometimes wonder what can be done if anything.
Tangent: On that topic, I often wonder about a new civil or criminal thing where someone file a suit / press criminal charges against someone for the offense of willfully spreading false information online, with the size of the penalty of the offense tied in some way to the harm amount and reach of that misinformation. The standard would be the same as today’s US defamation standard for public figures. “It is true” is an absolute defense, and the suer / prosecutor has to prove beyond a reasonable doubt that the speech is false, and that the speaker knew it was false (or acted with reckless disregard as to its truth). For any typical speaker, this would be an impossible burden to meet. However, for places like Fox News, there’s got to be a paper trail of their lies.
I believe that free speech does not and should not inherently protect lies. Free speech is to protect people speaking honestly and including those who unwittingly say false things. Again, free speech is not here to protect people willfully saying false things. Outlying lies is not an ethical problem to me. Instead, it’s a practicality problem. It’s a slippery slope problem. I tentatively believe that the proposal I identified above would do a lot of good with very little blowback.
PS: I think Facebook has started requiring that your account name must match your real life name, and this has been their policy for a while now.
Is this true in light of online video streaming? Without video streaming, it seems very plausible that this could be true. However, I find it harder to believe that spam emails and the like can really be 10x bigger than all video streaming.
Gerrard@#19:
I was going on dated information. Netflix has outstripped everything else for a while now. Whups!