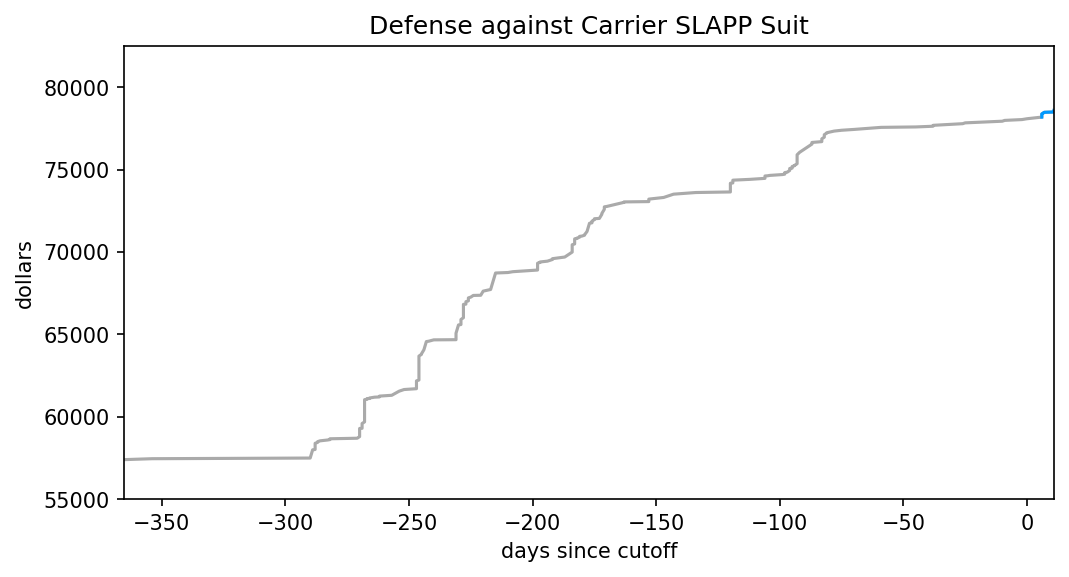
I know, it doesn’t look like it. Visit the legal GoFundMe, and you’ll see the current total is $79,760. And yet I said earlier that
As I type this, the legal GoFundMe sits at $79,650. Increase that above to $79,950, and I’ll switch from playing Super Mario World to Super Mario World Randomizer at the “Way Cool” difficulty on the 26th.
Some basic math reveals $79,760 is below $79,950, apparently well short of the goal. The missing piece is the very next sentence:
If you insist on donating only to FtB, instead of everyone impacted by Richard Carrier’s lawsuit, I’ll still count your donation towards that $79,950.
And PZ informs me that the PayPal link has raised a whopping $436.98 in one day! That math easily brings the combined total above $79,950, so it’s official. I’m playing Super Mario World Randomizer, thanks to your generosity!
But it’s going to be a pretty boring fundraiser if we hit all our goals in 24 hours. Thankfully, as I hinted at last time, I have quite a bit in reserve. Ever heard of a “Kaizo” game? Wikipedia has.
Kaizo Mario World, also known as Asshole Mario, is a series of three ROM hacks of the Super Nintendo Entertainment System video game Super Mario World, created by T. Takemoto. The term “Kaizo Mario World” is a shortened form of Jisaku no Kaizō Mario (Super Mario World) o Yūjin ni Play Saseru. The series was created by Takemoto for his friend R. Kiba.
Kaizo Mario World features extremely difficult level designs on the Super Mario World engine. The series is notable for deliberately breaking all normal rules of “accepted” level design, and introduced many staples of later Kaizo hacks, such as placing hidden blocks where the player is likely to jump, extremely fast autoscrollers, dying after the goal post and various other traps. This cruelty and the resulting frustration, as well as the skill level required, is both the purpose of the hacks and the appeal of any Let’s Play videos made of them.
The original hack was so popular that “Kaizo” became a generic term to mean any game mod that includes new levels and significantly amps up the difficulty of the original. As the name implies, Princess Kaizo Land is a kaizo game starring Princess Peach that’s significantly shorter than Super Mario World. It’s considered a “light” or easy kaizo, and has netted rave reviews. I’ve played a bit of it, but never passed the first level.
If you raise the GoFundMe to $80,850 before midnight MDT of September 25th, I’ll switch from playing Super Mario Randomizer (“Way Cool” difficulty) to Princess Kaizo Land. I know, that’s an increase of $1,200, but a) you’ve demonstrated you’ve got the funds at hand, and b) I really don’t want to play Pricess Kaizo Land. I haven’t played Super Mario World in ages, so my skills are pretty rusty. Even an easy kaizo game will be a big challenge! To preserve my sanity, I’ll guarantee to play at least four hours of Princess Kaizo Land, should the target be hit, but I can’t guarantee I’ll pass the game.
As before, any donations to the PayPal account also count towards this goal. My preference is that you donate to that GoFundMe instead of the PayPal link, though; the more cash we stuff in there, the more people will be free of legal debt. Still, it’s your money to do with as you see fit. I’m just happy you spent some of it to help others, in the face of all that 2020 has thrown at you.