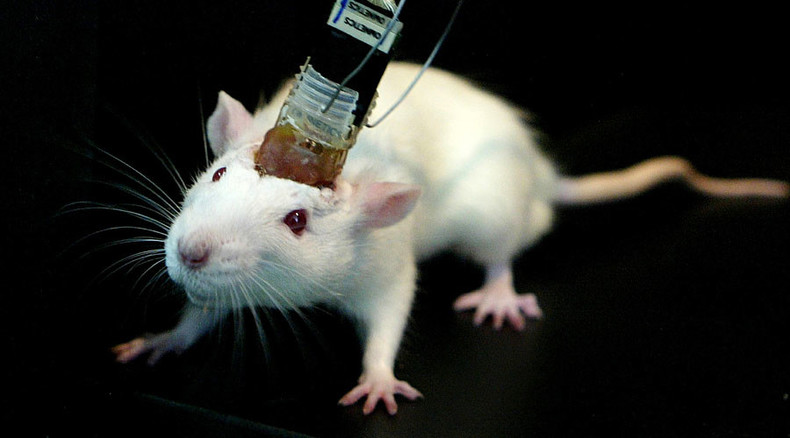
The Neuralink device has been implanted in one (1) person, Noland Arbaugh, so far. It’s not going well.
An estimated 85-percent of Neuralink’s brain-computer interface (BCI) implant threads connected to the first human patient’s motor cortex are now completely detached and his brain has shifted inside his skull up to three times what the company expected, volunteer Noland Arbaugh told The Wall Street Journal on Monday. Arbaugh also stated Neuralink has since remedied the initial performance issues using an over-the-air software update and is performing better than before, but the latest details continue to highlight concerns surrounding the company’s controversial, repeatedly delayed human implant study.
Neuralink’s coin-sized N1 BCI implant’s 64 wires thinner than a human hair are inserted a few millimeters into the motor cortex. Each thread contains 16 electrodes that translate a user’s neural activity into computer commands like typing and cursor movement. Around 870 of the 1024 electrodes in Arbaugh’s implant are no longer functional—an issue that allegedly took Neuralink a “few weeks” to remedy, reports The WSJ. When Arbaugh asked if his implant could be removed, fixed, or even replaced, Neuralink’s medical team relayed they would prefer to avoid another brain surgery and instead gather more information.
That device was inserted in January. In less than 6 months, it has decayed to 15% functionality, and the surgical team is reluctant to repair connectivity. That’s understandable; if the implant has basically torn out of place and built up scar tissue, there’s no point to sticking a second batch of wires into the same damaged spot, and relocating it to a new location is just going to tear up a different patch of Arbaugh’s brain.
The perils of being the first: you get to experience all the unforeseen problems, and also render yourself unsuitable for the Mark II device.
Oh well, too bad. Moving on, Neuralink is asking to stick wires in the brain of a second volunteer/guinea pig/sucker. There is no shortage of quadraplegics lined up for a miracle, and I can’t blame them.
The U.S. health regulator has allowed billionaire Elon Musk’s Neuralink to implant its brain chip in a second person after it proposed to fix a problem that occurred in its first patient, the Wall Street Journal reported on Monday.
Earlier this month, Neuralink said tiny wires implanted in the brain of its first patient had pulled out of position. Reuters reported last week, citing sources, the company knew from animal testing that the wires might retract.
The company intends to fix the problem by embedding some of the device’s wires deeper into the brain, the WSJ report said citing a person familiar with the company and a document it had viewed.
That last line is terrifying. Drill deeper! Get those wires in there, lock ’em in place, so if they do shift, they’ll rip up even more cortex! We better hope the second subject doesn’t know anything about the fate of the first.
This isn’t their only approach, though. They’re also thinking of patching the software. One of their goals is that Neuralink should be a discreet implant — I recall doing chronic implants in cats, where we’d get just one electrode in place, and lock it down with steel screws in the skull and great lumps of pink dental acrylic holding it down — which is obviously unsuitable for a human. So they have to make a small, low-profile device that operates on tiny voltages, and that also transmits and receives data to a larger, more capable computer. That’s a big constraint. Neuralink has put out a call for better algorithms, ones capable of a 200:1 lossless data compression with minimal computing power.
Turning brain signals into computer inputs means transmitting a lot of data very quickly. A problem for Neuralink is that the implant generates about 200 times more brain data per second than it can currently wirelessly transmit. Now, the company is seeking a new algorithm that can transmit this data in a smaller package — a process called compression — through a public challenge.
As a barebones web page announcing the Neuralink Compression Challenge posted on Thursday explains, “[greater than] 200x compression is needed.” The winning solution must also run in real time, and at low power.
Crucially, it specifies that the compression must be “lossless.” A “lossy” compression would be like a low-quality MP3 file, compared to pristine vinyl.
I know smart people are reading this blog. How about it? Get to work and write a revolutionary lossless compression algorithm that is capable of 200:1 reduction. I’m not a computer programmer anymore, so I’ll have to pass on the challenge, but I’m sure someone out there can do it…especially for such a great reward!
The reward for developing this miraculous leap forward in technology? A job interview, according to Neuralink employee Bliss Chapman. There is no mention of monetary compensation on the web page.
Although, to be fair, if you can write an efficient, fast 200:1 lossless compression algorithm, you can probably find better employment prospects than an Elon Musk company.
Also, there might be other reasons that Neuralink has invented what looks to be a hopeless task. They actually want the effort to fail.
Observers on social media immediately branded the task “impossible,” even speculating that Neuralink staff launched the challenge as a way of convincing the infamously incalcitrant Musk that it couldn’t be done.

Musk has a history of over promising and under delivering now.
The Boring company has gone nowhere.
Tesla EV cars is now in big trouble, laying off staff.
The self driving cars aren’t self driving.
He bought Twitter and quickly managed to all but wreck it as X.
Now Neurolink.
On the bright side at least for Elon Musk, he mostly uses the best money to lose, that is OPM, Other People’s Money.
Personally, I find this sentence far more terrifying.
“Hey guys. This thing you put in my head has gone horribly wrong and is messing my brain up and might even kill me. How about you fix it, replace it or, at the very least, remove it?”
“Can’t do that. We prefer to watch you die and gather more info. For science!”
Reminds me of this quote: It’s the second mouse that gets the cheese! What does the first mouse get? The mousetrap!
Electronic brain implants are already used in medicine, with a lot of success.
Nothing new about them.
One of the latest applications is Deep Brain Stimulation for Parkinson’s disease. Parkinson’s is a serious disease that is very variable and often also very undertreatable.
Electrodes in the brain, DBS, are also used to treat epilepsy and depression.
The company Neuralink needs to ask themselves why some neurological devices work and are FDA approved while their device is rapidly failing.
Can’t get it to work? Crowdsource that fucker. That’s never caused anything to awry.
Also, I don’t get the whole threads “retracting” thing. Is it the brain rejecting them as foreign material?
Stick a needle in jello, then wiggle the jello. The threads don’t retract, the whole brain wobbles around and the electrodes slide away.
@1– I keep saying it, but none of the media outlets seem to be asking the obvious question of why Musk, who hates paying tax and has taken stock options instead of cash in the past, suddenly wants a huge US$56B payout from Tesla.
Loctite.
raven @ #3 — I understand it’s a very small sample, but of the two people I know with some type of brain implant…one for Parkinson’s, one for epilepsy…both of them have been turned off. Not to say it isn’t worth a try but best if you’re dealing with an organization focused on medical outcomes rather than the bottom line and/ore the boasting rights of a crackpot boss.
I just looked at the Compression Challenge page — it doesn’t mention any reward at all, so even the job interview isn’t guaranteed.
I find it extraordinary that the CEO of three tech companies doesn’t have any software engineers that can work on this. SpaceX alone must have a serious comms team with lots of expertise in compression algorithms…could it be that his engineers told him what he wanted was impossible, so he brickwalled or sacked them and switched over to crowdsourcing?
I wonder if he will end up crowdsourcing a P=NP proof or a Maxwell’s demon heat pump in the next five years?
Speaking as someone who actually did grad-level work in compression/encryption/information theory… yeah, good f***ing luck.
The ‘lossless’ restriction is a killer in itself. Just the basic pigeonhole principle (if you have n holds and n+1 things to put in them, at least one hole is going to have more than one thing in it) says that no lossless compression algorithm is guaranteed to compress at all, because the set of outputs of the algorithm must be the same size as the set of possible inputs. If you feed random noise into a lossless algorithm, you’re quite likely to end up with something even larger than the original. (Granted, it never has to be more than one bit larger, as you can always get away with a single bit for ‘is the following data compressed or not’.)
The only way this would be even remotely possible is if the data being compressed allows it by being sufficiently structured and predictable. Plain English ASCII text can be compressed roughly 4x because with all the known letter frequencies and interactions the average amount of ‘information’ in a single character is only just over two bits. I’d be willing to guess that not only is the data involved here not compressible that much, we don’t even have a good idea of how compressible it is yet.
… I actually know someone I might be able to ask about the data, who works at a lab that actually does follow all the proper protocols. (I suspect mentioning ‘Neuralink’ would cause some epic rants.)
@11 jenorafeuer
And assuming you do get 200:1 lossless compression (which I think is highly unlikely) you then have to factor in the increase in latency introduced by the compression/decompression algorithm.
Compression is usually the more expensive part of the process and this is necessarily going to happen in the implant which is already subject to massive power and size constraints and the last place you would want a power hungry and heat dissipating module to reside. Imagine if you will an Nvidia GPU sitting inside your head to get a sense of how this could play out.
But I’m sure this will attract the perpetual motion, faster than light, ancient alien crowd of hucksters willing to fleece Nuralink of lots money so there is an upside to all this.
On top of all the failures of stupid ideas (boring was boring, neurakink slowly creates vegetables). the elongated muskrat is a rtwingnut ahole. I wish he would run out of money and STFU.
https://robertreich.substack.com/p/the-anti-democracy-alliance
Elon Musk and entrepreneur and investor David Sacks reportedly held a secret billionaire dinner party in Hollywood last month. Its purpose: to defeat Joe Biden and reinstall Donald Trump in the White House. The guest list included Peter Thiel, Rupert Murdoch, Michael Milken, Travis Kalanick, and Steven Mnuchin, Trump’s Treasury secretary.
Meanwhile, Musk is turning up the volume and frequency of his anti-Biden harangues on his X platform.
Since January, Musk has posted about Biden at least seven times a month, attacking the president for everything from his age to his policies on immigration and health. Last month, Musk posted on X that Biden “obviously barely knows what’s going on” and that “He is just a tragic front for a far left political machine.”
So far this year, Musk has posted more than 20 times in favor of Trump, arguing that he’s a victim of media and prosecutorial bias in the criminal cases that Trump faces.
jenorafeuer, please correct me if I am wrong, but I thought high lossless compression ratios are only achievable if the data itself is highly ordered or predictable. So if the data sets provided by Neuralink are noisy, then Musk is essentially asking for the impossible. (And I’m not even getting to the real-time with minimal computation wish!)
@12– Neuralink is very specific on this: ‘Compression must run in real time (< 1ms) at low power (< 10mW, including radio).’.
Yeah, Musk is a far right wingnut slime mold.
He also openly dislikes most of the human species on the planet and says so often.
I’m on his list of people to hate for several reasons, something I consider a minor accomplishment.
So why would anyone that Musk hates buy one of his Tesla cars?
They aren’t even all that good, problems with design, build, and styling as well as occasionally being death traps.
The short answer is that a lot of people won’t buy anything associated with Elon Musk. I won’t ever buy anything even remotely associated with Elon Musk.
Every time Musk insults one group or another, a thousand Tesla sales die.
Anyone could figure this out except reputed supergenius, Elon Musk.
Thanks, raven @3, for at least mentioning a name of a non-#QElon-owned company doing neural implants. It’s important to always remember that Theralink is neither the first nor the only company that exists in this business. We can’t let the least competent company pretend they’re the only act in town.
We can only hope that Flowers for Arbaugh is less of a tearjerker than the original.
Anybody remember the .com startup that claimed to have a compression algorithm that recursively reduced the file size? As I recall they got something like $10M from clueless VCs. They blew a wad on a “we flummoxed the suckers” party, the rest on a fancy office and the founders compensation, and quickly disappeared. If there’s anything left of their promotional material floating around the Web somewhere, it would be fun to flog it to the Muskrat and see if he bites.
@raven, all I know is that I see a LOT of Teslas on the road. If I were to get an EV, I’d be more likely to get a Rivian since they’re made practically in my back yard, but they’re still way more than I’m willing to pay for a car, gas or electric.
“A “lossy” compression would be like a low-quality MP3 file, compared to pristine vinyl”
Actually, it would be like an MP3 compared to an actual lossless format. Vinyl is full of distortion and lacks dynamic range. Pristine it ain’t. That’s why its adherents like it so much.
Just thinking of practicality, of course I understand quadriplegics wanting this device, and wanting it to work. They, like the Parkinson’s patients mentioned by raven @3, have a lot of gain in quality of life as a possible benefit.
But, will Musk’s implant ever really have a large consumer market? Are there a lot of people who want to pay, and can afford to pay, hundreds of thousands of dollars (no insurance coverage, of course) to have some surgeon (probably not even very skilled at this yet) saw their skull open and invade their brain, just so they can operate their phones with their thoughts? Hardly seems like a great benefit. I don’t foresee a lot of sales, even if it should ever work, which seems to have zero probability.
And then, all those billionaires who are cosying up to Trump? I don’t think that’s what they really want to do, they need to think ahead a little. If Trump’s elected, he’ll eventually (or right away) become a dictator, quite capable of manufacturing shows trials, fines, etc. What does Trump need and want? Money. Who has the money? Well, not for long. Will the billionaires’ working for Trump and publically licking his boots (Musk) stop Trump from confiscating large sums, even everything, from them? Not for a second.
If they flee to their boltholes in New Zealand, even easier to confiscate all they have as “crim.nal” fugitives from “justice.
They really haven’t thought this through, too gorram stupid, I suppose.
Implanting objects into your brain is simply unworkable from a structural perspective. It’s not going to remain in place, in addition to all the risks of infection having a direct pipeline into your brain.
Elon is doing an excellent job of being a comic book villain. I can envision him in 30 years as a shrunken bald headed madman, permanently wired into a robot body and cackling wildly.
@21 Scott Petrovits is correct. However, based on decades of study and experience, analog vinyl has many qualities that make it aesthetically pleasing, in the same way that the harmonic distortion of vacuum tubes is warmer and more pleasing than digital distortion. The equipment you use to play vinyl makes a lot of difference. If you use a high quality turntable, arm, and cartridge and pre-amp for a first playing while transferring it to clean high-bitrate digital you can get a very good rendering. My organization uses FLAC (free lossless audio codec) for audio and Lagarith (a free lossless codec) for video. Of course these don’t provide massively compact file sizes compared to funky lossy codecs like MP3. MP4 is better, visually, but still not nearly as clean as lossless encoding.
‘Stick that in your neural implant and smoke it.’
Re: #3. The depression DBS treatment can be extremely effective. It’s given my oldest kid a new life; motivation, good executive function, and something she’s wanted for over a decade, becoming a cyborg. (She has had a tshirt that read “Less Meat, More L33t”). But this treatment is bespoke – every brain is different, so the stimulation patterns have to be figured out for each patient. It’s something that takes highly trained neuromedical specialists – it’s not something that can go into mass production.
So Musk’s project is unworkable and will never be financially viable even if they get the implants to stay in place.
(Teyths, you are mistaken. Brain implants are workable, but somewhat dangerous. However, it’s being done, and done well. Just not by the Muskrat)
Forgot to add, it takes months of fiddling and testing to get a good pattern.
daulnay
Yes, but I’m referring to Muskrat’s terrible implant, which is doomed to fail because it won’t remain where it’s implanted. I am alarmed that despite not having FDA approval he has somehow managed to get it implanted into a human victim.
It’s very Flowers for Algernon
Presumably wired in using someone else’s brain implant tech? I can’t imagine him risking his own precious brain on this junk.
Then again, who knows. Maybe he already got one installed a couple of years ago. Random bits of loose wire slicing up his cortex might explain some things.
@chrislawson:
Noisiness is not a problem. The problem is that compression has an information theoretical lower bound that cannot be beaten. Basically, if the data is coming from a distribution X, then the entropy of X is minimum number of bits you will have to use to encode the data from X. Getting the exact entropy bound in most cases almost impossible but you can get close to it. The problem is that if the obvious ideas don’t work, usually you are mostly out of luck. So very likely neuralink is asking for the mathematical impossibility.
Ok, this is from the article:
LULZ. Good luck improving your compression scheme by a factor of … erm … 30 to 100 and while you are at it, why not square the circle at the same time too.
Indeed. The actual ask sounds like, “zip, but 100 times better somehow”. Which is stupid.
The underlying problem space might actually be slightly more interesting. If you allow “lossy” compression, it wouldn’t entirely surprise me if some of the techniques used in video compression wouldn’t work. Basically, that amounts to preemptively filtering various kinds of noise and non-perceptual detail, and then mostly sending only the changes (or rates of change), not the entire frames. Current generation video codecs do achieve compression ratios that are at least in the right order of magnitude. That sort of thing might be somewhat computationally intensive for a tiny medical device, but it’s apparently only ~1000 ‘pixels’ in the current device anyway, so does seem at least theoretically tractable to me.
The problem, aside from busting the “lossless” requirement, is that to know how to design that algorithm, you’d need to be armed with all kinds of detailed empirical data about what “perceptually important” means in this context. Which I very much doubt anyone does know much about yet. Certainly not the ‘catlitter69’ types that are going to be responding to this little call to arms.
@31 Like you, my first question was: do they know their data? Then, have they published any?
Obviously no general compression algorithm will come close to 200:1 compression. But IF the data has identifiable noise that can be removed (and optionally just the length of it sent), AND IF the non-noise consists mostly of information units amenable to dictionary lookup and other low-watt compression techniques, then it might be doable. But one must first separate the wheat from the chaff, and then analyze the hell out of the rest. It’s a hopeless task unless you can get your hands on a metric ton of actual data from the device. Have they published any? If not, how do they expect anyone to waste time trying to write a custom algorithm tailored to that data?
@32 Oops. Meant to say ‘analyze the hell out of the wheat’.
@32:
They have released a data dump, of sorts: “To kickstart the challenge, Neuralink released one hour of raw brain recordings from a monkey playing a simple video game.”
The actual data is here.
It takes the form of several hundred 5-second .wav files. I suppose each one is the sequence from an individual electrode? (10 bits @ 20kHz, apparently). It’s entirely without context though, aside from the basic fact that it’s a primate playing a game. There doesn’t appear to be any manifest, any information about where the electrode is, proximity to others, what control input the monkey was making, etc.
Audibly, they all sound like something like a radio tuned to empty air, or a waterfall on rainy day. Pink noise, with perhaps a little extra static layered on. Super compressible, I’m sure. /s
@32:
There is a small amount of sample data (for testing the compression algorithm) available for download at their link above. Looks to be just over an hour’s worth of single-electrode data split into 5 second 16-bit (they say the electrode data is 10-bit) 19531Hz PCM WAV files.
Looks pretty noisy – we’re not talking a nice clean single-neuron output here, but an average over a chunk of brain.
The lossy/lossless question also depends on the use the data is being put to. If you just want to make something that works, and you already know the theory, then my guess would be you could tailer a lossy algorithm to the data very well indeed. However if you’re still trying to figure out what is important or not then you probably can’t afford to throw much away initially, and if you want to publish papers on it then I imagine reviewers would give a bit of side-eye if you tried to say “we took this noisy data that no one else has been able to figure out before, ran it through a randomizing filter, then decided the output of that has these important features…”
Hmm. Actually, it’s even worse than I thought:
The article claims it’s “1 hour of data”, but the files are 5s long. It’s not an encoding issue, b/c my player seems to be registering the right sample rate (19kHz, close enough).
But there are 743 files, and 7435 = 3715s, which is pretty close to an hour. So presumably they’re are all sequential data from the *same electrode.
So that means there’s zero data there about, e.g., whether noise or signal from electrodes in different regions might be correlated. There isn’t even really a sequence: the files aren’t numbered, they’re named with random-looking UUIDs.
It’s just a bunch of “data”.
@36:
Yup. My guess is that they just want something that works on “data like that” without having to reveal to much about their data. But you could probably do a pretty good job of stitching the files back into the right order again by comparing end samples. Assuming they are indeed consecutive sections from a single electrode.
The data itself looks like it’s been scaled by 2^5 to get the sample to fill half of the 16-bit PCM range, but not perfectly – it’s not a simple shift-right as many of the lsbits are kinda-but-not-very variable. Again, you probably could with a bit of work figure out and invert the exact transform to recover the original raw 10-bit sample values. Given that, the electrode gain appears to be set such that the samples occupy a little over a half of the available 10-bit range, which feels like a reasonable choice.
It sounds like you’ve poked at the data more than I bothered too, but it seemed noisy enough to me that I wouldn’t necessarily expect any reliable correlation from one sample to then next. Unless they deliberately included some overlap, I suppose — there do seem to be a couple extra megabytes then there should be. But it’s still weird. I suppose matching up and joining the files should be child’s play to anyone capable of solving the problem. But what’s the point? Why not just label the files properly? Or pack it in a single 60-minute file to begin with?
And what you’re looking at in the encoding seems a bit strange too. I’m not actually sure scaling it into the 16 bit range does make any sense.
If this were about the analog values, than maybe. Indeed, the .sh script that checks the results looks like it plans to read in similar PCM data under a ‘.brainwire’ extension, which suggests this all might be a format used internally by their analysis tools.
But this is supposedly about accurately encoding the low level bits, not an intermediate analysis format. And the scaling/transformation isn’t even documented. The first thing you’d have to do is reverse engineer it, in order to obtain the 10-bit values, and not scaled 16-bit stuff that’s already 60% more bits than you need. (It’s actually kind of funny that they’re basing the compression ratio calculation off of 143M uncompressed size, when the significant content is more like 85M right from the beginning.)
Why would they not simply leave the high bits zero to avoid any mixups? Or use a custom file with a more tightly-packed 10-bit format, rather than 16-bit PCM?
These might seem like minor quibbles, but it all kind of adds up. It looks to me like rather than a proper sample of raw sensor data, someone just copied or exported some pre-scaled, maybe even partially processed data from their internal analysis suite, more or less literally filed off the serial numbers, and ran ‘zip’ over the resulting mess. Possibly someone who doesn’t even know what the raw data would look like.
At the very least, it suggest a lack of attention to detail. The whole thing seems deeply unserious.
“Deeply unserious” sounds pretty accurate here. The very least they could have done is give those WAV files more descriptive or sequential filenames. And publicly saying they’re “looking for new approaches to this compression problem, and exceptional engineers to work on it?” What a joke. Shouldn’t they have found “exceptional engineers” at the START of their big project? That’s what companies normally do.
@1 & @7 A lot of the money, at least $25B of the $42B, Elon was forced by a judge to pay for Twitter, can from the Saudi sovereign wealth fund. And they want what they were promised. It’s very much a Goodfellas-style, “Fuck you, pay me,” situation. And if he doesn’t pay them, he might just find himself walking backwards out of a hotel and into a suitcase.
Raging Bee:
You mean, they did less than the very least?
No, of course you don’t mean that.
You mean that they did less than your minimum acceptable least.
Got it.
(Properly expressing one’s intended meaning, not so easy sometimes)
—
Perhaps it’s possible that they did no more and no less than what they intended to do with that data provision?
Not saying it’s some sort of filter, but not saying it ain’t, either.
Not saying your comment has any meaning, but not saying it don’t, either.
It means that maybe it was some sort of test. Some selection protocol.
That perhaps the way people who respond to it respond might be what they seek.
Maybe something else.
Not everything is transparent, Raging Bee.
And it’s not always incompetence.
The rabbit hole really is bottomless.
One of the sentences at the beginning of that data page was bothering me:
A power and complexity budget makes sense, of course, but that’s not helpful. “Including radio”? WTF? How am I supposed to know how many mW your radio uses, idiots? Why would I care? Just tell me what I can use. And less than 10mW and 1ms on what exactly? A millisecond on a low power micro or DSP is very different from one on a top-of-line Nvidia chip… (Given that their hardware is supposedly some state of the art custom ASIC, what might make the most sense would be to define the budget in terms of something like gates or FPGA luts. Or maybe cycles on a common emulated CPU. This is just word salad.)
Anyway, I thought I’d google a bit to see if there were any specs floating around about what kind of processing hardware might already be on these chips. I found this gem.
It’s a write up of what’s known about the chip, nominally based on patent filings, but clearly leaning at least as heavily on press events. It’s a mix of irrelevant technical detail and absolute bullshit, seasoned with math errors. Content mill chum put out by some kind of investment hype tank.
But, I still learned something. Like, did you know that:
In fact,
That was at least 2 years ago! And that spike detection stuff sounds like a great idea! Exactly the kind of domain-specific solution that could crack this problem wide open. I reckon they’ve got this compression thing licked. What do they need help for? There are even all kinds of details about the precise details of an on-wire symbol format for sending the info about spikes and whatnot.
Hmm. Those numbers are kinda weird though. They look…familiar. Strange that they had a working solution achieving 200X compression in 900ns several years ago, and now here in 2024 they need an algorithm for…[checks notes]…200X compression in “< 1ms”.
Yikes.
I’m actually genuinely curious what the story is here now. I know the basic foundation is boring hype and lies. But how did this stupid call for help and “data” release happen, exactly? From the perspective of dysfunctional institution forensics, what’s the actual internal sequence of events?
(BTW, turns out the real technical problem here is…bluetooth. That’s where the 1Mbps bandwidth budget, and thus 200X ratio, comes from in the first place. They’re using friggin bluetooth. At Basic Data Rate, no less.
A serious organization might entertain the idea that a low speed radio technology from 20 years ago might not be a good fit for a state of the art medical device generating 200Mbps or more of data. Maybe there are higher bandwidth solutions, with even lower power requirements. Off the top of my head, it seems like some kind of near-infrared transmitter coupled to an external receiver worn on the scalp somewhere might be something to look into. Good transmission through fleshy bits, used for everything from on-chip photonics to deep space networks, at phenomenal data rates. Hmm.)
It also means speculating absent sufficient information, never mind perspective or context, is not all that rewarding an endeavour.
A lot of the money, at least $25B of the $42B, Elon was forced by a judge to pay for Twitter, can from the Saudi sovereign wealth fund. And they want what they were promised.
What, exactly, were they promised? Has anyone connected to said sovereign wealth fund made any public noises about not getting what they were promised?
I suspect the Saudis were promised a Xhitter made safer for fascists and tyrants; and that’s what they got. That’s my guess, and I’m stickin’ to it, at least until the Saudis actually sue #QElon for some other promised benefit.
@jack lecou:
I’m guessing some fuck up, buggy implementation, or lossy compression and so on, combined with extreme incompetence and thus lack of common sense to tick of alarm bells that those numbers are too good to be true. As others have noted, even the formulation of the challenge clearly shows that they are absolutely fucking clueless with respect to anything to do with compression. I mean, for fucks sake, it’s pretty easy to come up with a lower bound on the entropy of whatever you are trying to encode and thus figure out at least one limit on the compression ratio of a lossless compression scheme but it sounds like they can’t even do that.
I think the only thing that would stop Musk would be finding out he was running a Ponzi scheme. I don’t think he’s stupid enough/or greedy enough to do it, but….. this is Musk we’re talking about.
In case it wasn’t clear, my vote is all of the above, with a big helping of “they never actually had that working at all”. The specs haven’t changed, because that need is driven by the hardware design choices. So they staged a demo where it “worked”, and did the thing where you tell everyone it works and then try to actually make it work later. Except this is a harder problem then they expected.
This is just “Full Self Driving!” but for brain wafers: “It’s working perfectly! You want to use it now? Well, it will be ready in… 6 months.”
The only weird thing is this challenge part. It’d be like Tesla casually dropping a, “Hey, internet, apropos of nothing, does anyone know how to write a program to drive a car without bumping into anything?” It reveals a little too much.
Not only that, but they’ve also mangled the problem, in a run-back-and-forth-through-auto-translate sort of way where key technical details and requirements got lost. For example, it’s clear that for the real problem, some kind of lossy, domain specific detail extraction and encoding would be perfectly acceptable, if it worked. No doubt that would be very difficult, but at least not a priori impossible. That’s what they originally anticipated doing.
Somehow that’s now mutated into a re-statement of the problem that makes it literally mathematically impossible.
chrislawson@14:
Yes, that’s basically what I said, “The only way this would be even remotely possible is <em<if the data being compressed allows it by being sufficiently structured and predictable.”
steve oberski@12:
Agreed… I wasn’t even talking about power constraints yet, I was just going with ‘even with no other constraints the request as written violates basic principles of information theory’.
My own thought is that if you want that sort of compression ratio, you’d be looking at really domain-specific lossy compression, probably something along the lines of a wavelet compression, but customized based on what we know about the shapes of the current spikes produced by neurons.
My understanding is that, in labs that are doing this sort of research with proper controls, in general the reading of data is done mostly in analog form, piped out via a thick bundle of cables, and that any actual compression and analysis are done outside the skull for exactly the sort of heat and power availability issues mentioned. (Said labs also tend to be very focused on making sure the connections for the cable plug stays clean and the monkeys stay happy, both because he people doing this aren’t sociopaths, and because happy monkeys provide better data.)
Which is to say that, yes, we’re at least a couple of tech generations away from being able to get anything that could just be installed into someone’s skull and left there. The research as to what we can do with something that could safely be installed in a skull is still ongoing.
Some of the notes above about previous claims of such a compression algorithm having been found already are quite telling… and more indications that Neuralink is running on a venture capitalist mindset rather than an academic mindset. Which is, of course, no surprise with Musk involved. “Bullshit to get the money flowing and then hope we can actually deliver on things we promised but haven’t adequately studied yet” is something that shows up a lot in Musk’s businesses. SpaceX and Tesla have had a number of successes, sure, but in both cases the successes were generally in the parts that had actually been studied for years and we mostly knew how to do in broad strokes if not in details, and mostly just needed the investment so the current design work could actually be completed. (People have been studying electric cars at least since the 1980s.)
raven @ #3;
My girlfriend has a DBS implant for her early onset Parkinson’s and it has been spectacularly succesful at improving her quality of life by it’s control of her dystonia.
It’s techology is nothing at all like Musks’ intentions and is not comparable at all – the only similarity is that both involve brains and electricity – DBS is in no way attempting information transfer.
That DBS is possible and effective does not suggest anything useful or informative regarding ‘neural link’ type devices.
#22 @ garnetstar
You are correct that capitalism drives this. You are not correct as to the target market. People who are disabled are driving their pretext both for rhetorical seemingly-like-human reasons and for avoiding-government-regulation reasons. You have made a true statement. …kinda sorta?
This is not at all the why they are doing this.
They are hoping for casual users. People have smart appliances and wear VR hoods and cars that back themselves into ponds where their doors stay closed and they can’t get out. These consumers do these purchases on purpose. They have m-o-n-e-y.